
Natural Language Processing (NLP) is a branch of computer science that is concerned with how humans and computers interact with each other. More specifically, NLP refers to the field of Artificial Intelligence or AI and is concerned with giving computers the ability to understand the contents of documents (text, spoken words, etc) in a smart and useful way like a human being can.
Humans speak and write in a variety of languages, including English, Spanish, Bangla, and others, but computers can only read machine code or machine language. NLP tasks break down human text and speech in such a manner that computers can understand human languages not only the words but also the concepts and how they are connected together to construct meanings. Spam detection, text mining, machine translation, virtual agents and chatbots, automated question answering, and more applications are used in the NLP field.
NLP is a tremendously exciting field that has seen rapid progress in both quality and usability in recent years. Now, in the field of STEM(Science, Technology, Engineering, and Mathematics), NLP is one of the most popular research topics. From the below projects you can get ideas for your Natural Language Processing final year project.
1. Time Series Analysis with Facebook Prophet Python and Cesium
This project focuses on forecasting healthcare call volumes using Facebook Prophet and Cesium for feature extraction. We clean and prepare the data, extract statistical features (mean, standard deviation, skewness) using Cesium, and enhance the dataset before feeding it into Prophet for accurate forecasting. The model predicts future call volumes for the next 12 months, capturing trends, seasonality, and uncertainty intervals. The final results are visualized to interpret the key factors influencing predictions, combining historical data trends with optimized feature extraction for improved accuracy.

2. Stock Market Volatility Forecasting Using ARCH and GARCH in Python
This project focuses on forecasting stock market volatility using ARCH and GARCH models. By analyzing historical stock data, we predict future market fluctuations, helping traders and investors manage risks. The workflow involves loading and preprocessing stock price data, conducting exploratory data analysis (EDA) with rolling volatility, return distributions, and stationarity tests.
The ARCH and GARCH models are fitted to the stock returns data, and their performance is evaluated using Mean Squared Error (MSE) and Mean Absolute Error (MAE). Finally, forecasted volatility trends are visualized to compare the accuracy of both models. The project provides a practical way to analyze market patterns and improve risk management strategies.

3. Book Recommender System Using TF-IDF and Clustering
This project focuses on building a book clustering and recommendation system using TF-IDF and machine learning techniques. It analyzes book metadata to identify patterns, group similar books using K-Means and hierarchical clustering, and recommend books based on cosine similarity.
The workflow starts with data cleaning and preprocessing, followed by text vectorization using TF-IDF to extract key features. Books are then clustered into meaningful groups, and a recommendation system suggests similar books to users. The results are presented using interactive visualizations like treemaps, dendrograms, and grid views for better user engagement. Whether you're a book lover or a data enthusiast, this project offers a fun and insightful way to explore book recommendations.

4. Multi-Class Text Classification Using RNN and LSTM
This project focuses on automating text classification using Recurrent Neural Networks (RNN) and Long Short-Term Memory (LSTM) models. It classifies real-world customer complaints into categories such as identity theft, credit card fraud, and billing issues using deep learning and NLP techniques.
The workflow starts with data collection and preprocessing, including text tokenization, noise removal, and word embedding with GloVe. The dataset is split into training, validation, and test sets, and models are trained using cross-entropy loss with Adam optimization. Model performance is evaluated using accuracy, confusion matrices, and classification reports to ensure high accuracy in predicting text categories. This project offers a practical approach to NLP, deep learning, and AI-based problem-solving.

5. Document Summarization Using SentencePiece and Transformers
This project focuses on automatic document summarization using SentencePiece and PEGASUS Transformers. It leverages deep learning to generate concise and meaningful summaries from long texts, making information processing more efficient.
The workflow begins with loading and preprocessing the SAMSum dataset, which contains dialogue-based texts. The PEGASUS model is fine-tuned using Hugging Face Transformers, and input text is tokenized with SentencePiece for better model comprehension. After training, the model is evaluated using ROUGE metrics to ensure accuracy. Finally, the fine-tuned model is tested on real-world examples and saved for future use, making document summarization fast, effective, and scalable.

6. Semantic Search Using MSMARCO DistilBERT & FAISS
This project builds a semantic search engine using MSMARCO DistilBERT for text embeddings and FAISS for fast vector-based retrieval. It processes movie plot descriptions, converts them into high-dimensional vectors, and indexes them in FAISS for quick similarity search. When a user enters a query, it finds the most relevant results based on cosine similarity. This system enables context-aware search, making it ideal for movies, e-commerce, and healthcare applications.

7. Question Answering System Using DistilBERT
This project builds a Question Answering (QA) system using DistilBERT trained on the SQuAD dataset. The model can read a passage and accurately extract answers to user queries.
The workflow involves loading and preprocessing the dataset, tokenizing questions and contexts, and fine-tuning the DistilBERT model using Hugging Face's Trainer API. After training, the model is evaluated with accuracy and F1-score and tested on new queries. Finally, the trained model is deployed on Hugging Face Model Hub for public access, making it a powerful NLP-based Q&A tool.

8. Word2Vec and FastText Word Embedding with Gensim
This project explores word embeddings using Word2Vec (CBOW & Skip-Gram) and FastText for text analysis and visualization. The models capture semantic relationships between words, enabling tasks like word similarity, analogical reasoning, and anomaly detection.
The workflow includes data preprocessing, training word embeddings, and evaluating models using cosine similarity and analogy tests. PCA and t-SNE are used to visualize word relationships in 2D. This project compares CBOW, Skip-Gram, and FastText, highlighting their effectiveness in capturing word meanings and context.

9. Beginner NLP Project: Text Processing and Classification
This project introduces Natural Language Processing (NLP) techniques for text classification using Python, NLTK, and Scikit-learn. The goal is to classify text sentiment (positive, negative, or neutral) using Logistic Regression.
The workflow involves text preprocessing (tokenization, stopword removal, stemming), feature extraction with CountVectorizer and TfidfVectorizer, and training a classification model. The model is evaluated using accuracy, confusion matrices, and classification reports. Results are visualized with Matplotlib and Seaborn, making it an excellent hands-on introduction to NLP-based text classification.

10. Skip-Gram Model Implementation for Word Embeddings
This project explores word embeddings using the Skip-Gram model in PyTorch, converting words into numerical vectors that capture semantic relationships. It is widely used in search engines, recommendations, and text categorization.
The workflow includes data preprocessing, building a vocabulary, and training a Skip-Gram neural network with negative sampling. Word embeddings are then visualized using t-SNE, revealing semantic word clusters. The model is evaluated by measuring word similarity and distance, making it a powerful tool for NLP applications.

11. Sentiment Analysis for Mental Health Using NLP & ML
This project applies Natural Language Processing (NLP) and Machine Learning (ML) to classify mental health statements into relevant categories. By leveraging TF-IDF feature extraction, text preprocessing, and machine learning models, it aims to identify emotional patterns in text data.
The workflow includes data cleaning, tokenization, stemming, and feature extraction. Class imbalance is handled with Random Over-Sampling, and models like Logistic Regression, Decision Tree, Naive Bayes, and XGBoost are trained. The best model is optimized, evaluated with accuracy and confusion matrices, and saved for future predictions. This project enhances mental health awareness using AI-driven sentiment analysis.

12. Topic Modeling & Sentiment Analysis of Customer Reviews Using K-Means Clustering
This project analyzes customer reviews using sentiment analysis, topic modeling, and clustering techniques. Reviews are preprocessed using NLTK, tokenized, and lemmatized for consistency. Sentiment classification is performed using Random Forest, Naive Bayes, and Logistic Regression, labeling reviews as positive, neutral, or negative.
For topic modeling, LDA (Latent Dirichlet Allocation) extracts hidden themes, while K-Means clustering groups similar reviews based on TF-IDF vectors. The results are visualized with word clouds, heat maps, and clustering plots, offering insights into customer feedback patterns.

13. Hybrid Recommender System Using LightFM in Python
This project develops a hybrid recommendation system combining collaborative filtering and content-based filtering to provide personalized product suggestions. It integrates customer purchase history, product attributes, and customer segments to enhance shopping experiences and boost sales.
Using LightFM, the system processes user-item interactions and item-feature associations. The model is trained and evaluated using the AUC metric, ensuring accurate recommendations. Sparse matrices optimize performance, making it scalable for large datasets. The final system delivers highly relevant product recommendations based on customer behavior and product characteristics.

14. Customer Service Chatbot Using LLMs (Mistral 7B Instruct)
This project builds a customer service chatbot using Mistral 7B Instruct, a cutting-edge Large Language Model (LLM). The chatbot understands and responds to customer queries naturally while ensuring fast, scalable, and cost-effective support.
The workflow includes fine-tuning the model on real-world customer service conversations using SFTTrainer and Position Embedding Free Transformers (PEFT) for efficient training. Gradient checkpointing and quantization improve memory optimization and speed, making real-world deployment smooth. The chatbot is tested and integrated into various communication platforms, providing 24/7 automated customer support with high accuracy and contextual awareness.

15. Next word prediction using LSTM
Next word prediction is one of the fundamental tasks of NLP. People are often searching for something on the browser, after typing one or more words then the browser is trying to predict the next word that the user is looking for. In this project, they have used the previous three words to predict the next word.
The main challenge is how the browser predicts the next word. Here, you can find they have used the Long Short Term Memory (LSTM) model to overcome this challenge.
You can follow this video tutorial to know how you can use the LSTM model to create your own "next word prediction" project.
16. Suicide Ideation Detection Using NLP Analysis
According to the Centers for Disease Control and Prevention, there were over 48,000 suicide-related deaths in the United States in 2017, with 14.8 suicides per 100,000 persons. The evidence that the Internet and social media can influence suicidal behavior is rising.
Here, they have analyzed the "Suicide Ideation" article that was posted on social media, and have found out about suicide ideation. Suicidal ideation sentiment analysis and subsequent suicidal ideation identification are also part of the study. In this article, you can learn how they have detected which one is Confirmed Suicide Ideation and which one is Rejected Suicide Ideation. At first, they collected a dataset from social media (Twitter), then processed the data using TDF-ITDF. To find the output result they have followed Machine Learning techniques (Naive Bayes, SGD Classifier, Logistic Regression, Random Forest).

For more information about this project, you can follow this article.
17. Spam classifier in python
If you are starting out in Machine Learning and deciding to create a classifier project, then a spam classifier is a good choice for you. Here in this project, you can learn how to create a spam classifier project to detect an SMS is ham or spam. Here they have used stemmer and lemmatizer to find out the root word from the sentence of an SMS and use the Naive Bayes Model to classify the SMS as spam or not spam.
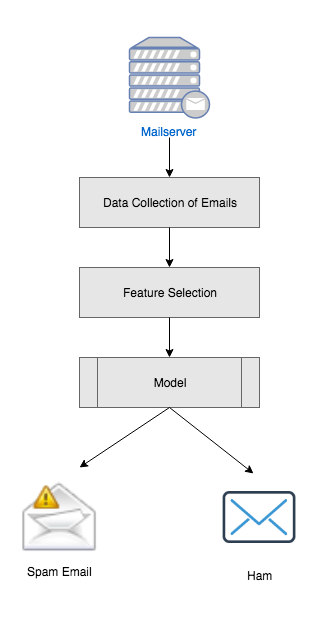
For more information about this project, you can follow their video tutorial and GitHub for source code.
18. Faker News Classifier Using LSTM
Now the day's News Channel writes lots of news about what is happening all over the world. Some of this article is intentionally and verifiably false, But they did not acknowledge that. Some false information creates a negative impact on our people, government, also on our economy. So it is important to identify the fake news from the authentic news.
Here in this project, you can learn how their LSTM neural network model identifies fake news. At the very first they have taken some sentences from the news article, then use the stemmer to find the root words and preprocess the data, pass it to the LSTM classifier layer to train the model, and finally, the model will predict the test data.

For more information about this project, you can follow their video tutorial and GitHub for source code.
19. Sentiment Model Using BERT
Sentiment analysis is one of the most important tasks in the field of Natural Language Processing (NLP). Actually, it is used to predict users' product reviews, whether they feel positive, negative, or neutral about it.
Here, you can learn how to create your own sentiment model and train the model in a better way using the BERT (Bidirectional Representation for Transformer) as an encoder stack of transformer architecture.
You can follow this video tutorial to find out how they have created the BERT model, loaded the IMDB Movie Reviews dataset, trained their own model, and then have done inference using flask.
20. Sarcasm classifier
Sarcasm is the use of words that signify the exact opposite of what you are trying to express, usually to insult someone, or just be funny. In two ways we can identify a sentence is sarcasm or not. The first way is, we need some sarcasm sentences and then we match our input context with that. And another one is, to find sarcasm from our human experiences.
Here in this project, you can learn how they have classified a sentence as sarcasm or not. At first, they have to convert the input text into a series of vectors, then pass it to the LSTM (Long Short Term Memory) model, then the model produces a number that will tell you the probability of that particular text belonging to sarcasm or not.

For more information about this project, you can follow their video tutorial and GitHub for source code.
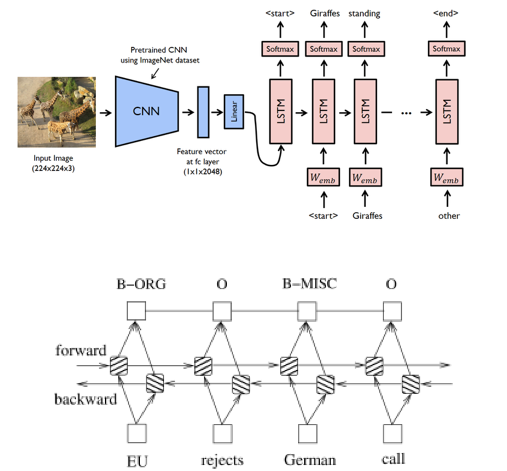
21. Image-Caption Generator
Image Caption Generator is a popular research area of computer vision and NLP whose task is to understand the context of an image and describe it in natural language. Being able to recognize the content, how those are related to each other, and describe them in a meaningful sentence is very challenging.
Here is a project where they will handle this challenge using CNN (Encoder) as an "Image Model" and RNN/LSTM (Decoder) as a "Language Model". And for training, testing, and evaluating the image caption there have been used the Flickr 8k dataset.
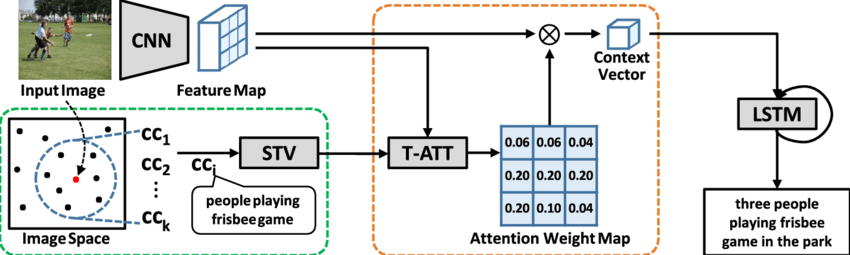
In this project, you can understand how they are able to create an Image Caption Generator from some meaningful context, which gives you a better idea to create your own project.
For more information about this project, you can visit their official website and GitHub for source code.
22. Personal Voice Assistant
A voice assistant is a software program that can perform particular voice commands and deliver the user with relevant information that the user is looking for.
Here in this project, first, they create a voice recognition software for interpreting (analog signal to digital signal) user voice commands. After that computer takes the digital signal and uses a language processing algorithm to match it up to words, and works on what the user is looking for, then creates a voice synthesis method for converting the text to speech.
Here, you can find a proper guideline to create your own voice assistant from scratch to an advanced level.

For more information about this project, you can visit their official website and GitHub for source code.
23. Compare documents similarity using Python
Document similarity is defined as how close two documents of text are in comparison to each other. It is a very common task of evaluating document similarity between two documents in NLP. It plays a vital role in many microservices with information retrieval and translation function. If you are interested in how to find the similarity between two documents, first you have to understand the simpler metrics that can quantify the similarity between texts.
Here in this project, you can learn how they have built a web application that will compare the similarity between two documents. Which can help to build your own Natural Language Processing final year project.
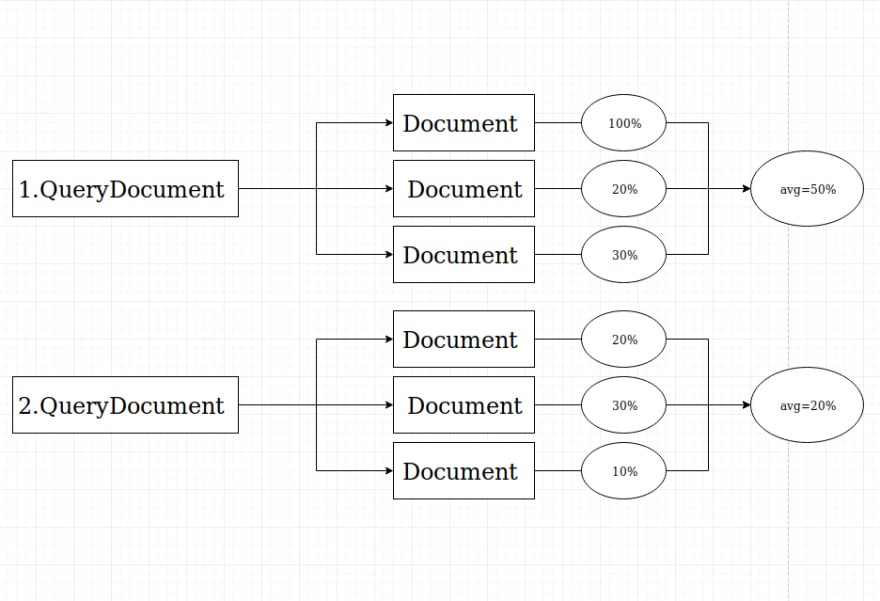
For more information about this project, you can visit their official website.
24. Inference-based Chatbot system
In recent years, the deployment of chatbots has exploded in a variety of sectors, including marketing, support systems, education, health care, cultural heritage, and entertainment. Here in this project, they have created it for self-driving cars, and for playing GTA stream. But you can use it for your own purpose. Actually, they have built a Chatbot using TensorFlow's sequence to sequence library, and for the dataset, they have used Reddit comments.

Here you can learn how to create a very basic Chatbot using Python's NLTK library and then you can build your own Chatbot.
For more information about this project, you can visit their official website.
Here you will find some NLP-based projects that are being helpful.
If you have any suggestions or queries you can comment below. Your comments are always important to us.






