- Introduction to Deep Learning
- Data Preprocessing for Deep Learning
- Convolutional Neural Networks
- Recurrent Neural Networks (RNNs)
- Long Short Term Memory (LSTM) Networks
- Transformers
- Generative Adversarial Networks
- Autoencoder
- Variational Autoencoders
- Diffusion Architecture
- Reinforcement Learning in Deep Learning
- Optimization Algorithms for Deep Learning
- Regularization Techniques
- Model Tracking and Accuracy Analysis
- Hyperparameter Tuning Techniques
- Transfer Learning
- Deployment of Deep Learning Models with REST API
- Deep Learning on Cloud Platforms
- Mathematical Foundations for Deep Learning
Diffusion Architecture | Deep Learning
Over recent years Generative Adversarial Networks(GANs), Variational Autoencoders(VAEs), and the family of flow-based generative networks have been widely used in generating realistic samples with impressive performance and some limitations. More complex generative models like diffusion probabilistic models have been developed to overcome the limitations and improve the performance of generating realistic samples. GANs are well-suited for generating new data samples(sharp realistic samples) but the model can be affected by mode collapse and the model depends on the two different models and adversarial process. Variational Autoencoders give a more stable network than GANs but it can’t generate the more sharp new samples like GANs. On the other hand, flow-based generative models need complex and computationally expensive architectures and produce less diverse realistic samples. Also, it needs high memory to process the model. So, a generative model is needed that is stable in training, generate sharp synthetic data, computationally not hugely expensive. That’s why the diffusion model comes in front of us.
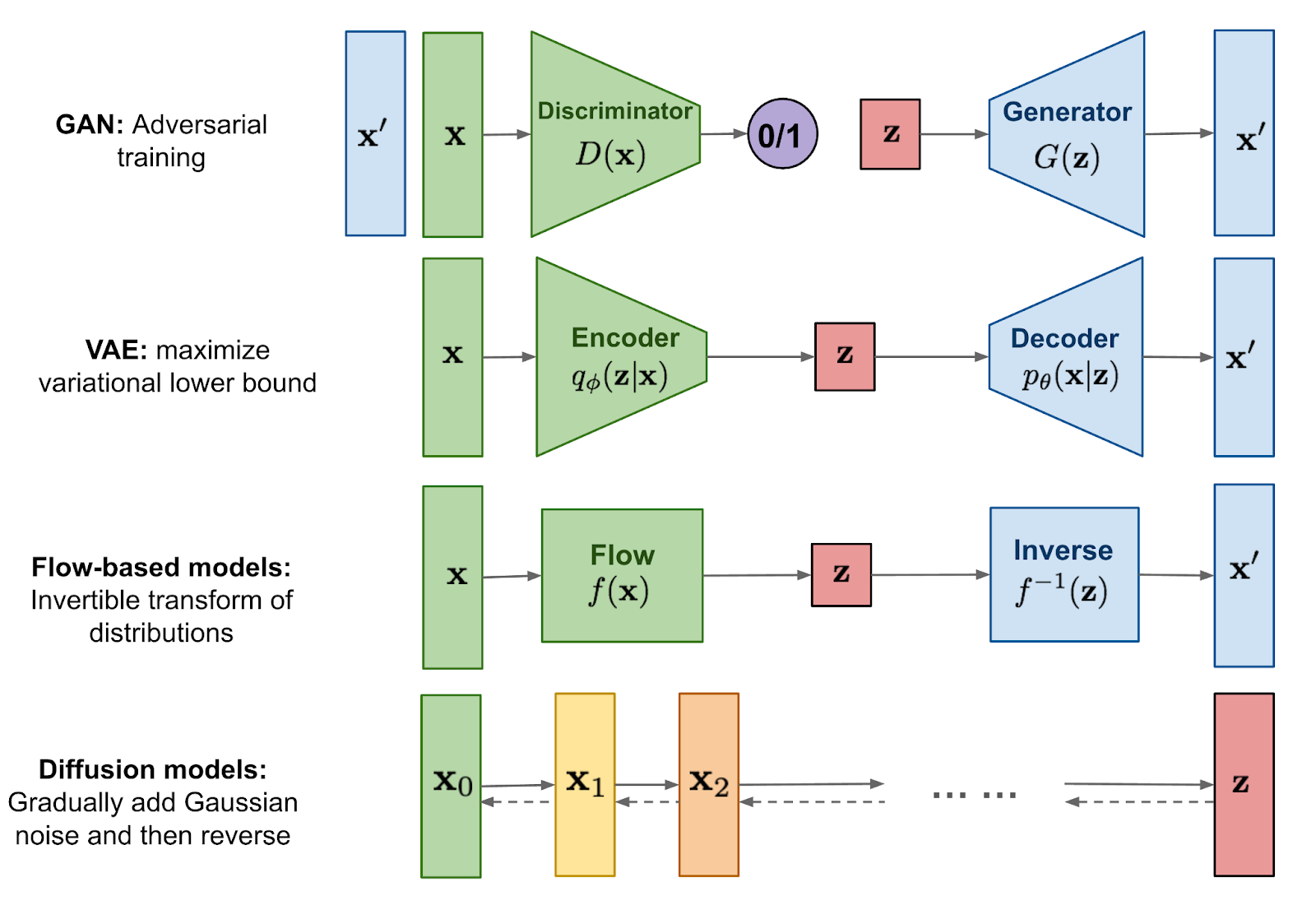
Today we will discuss the diffusion models in-depth with implementation. Before jumping into the details of the topics, look at the overview of the topics below.
Introduction
The architecture of the diffusion model & the process of working on the model
Implementation of diffusion model
Conclusion
Introduction
Diffusion models are a class of probabilistic models that systematically and slowly destroy the structure in a data distribution and turn it into noise through an iterative forward diffusion. Then learn a reverse diffusion process that restores the structure of the data and removes the noise and returns a highly flexible generative model. This is the approach of Diffusion models that allows us to learn rapidly and evaluate probabilities in generative models.
The idea of the diffusion models comes from the diffusion process in non-equilibrium statistical physics. Diffusion models were first introduced in 2015 by Sohl-Dickstein and the title was ‘Deep Unsupervised Learning using Nonequilibrium Thermodynamics’. In 2020, Ho et al. published a popular paper named ‘Denoising Diffusion Probabilistic Models (DDPM)’. We will learn the details in the following topics. Let’s know about the benefits and applications of Diffusion models.
The benefits of Using Diffusion models
We have already been told that GANs, Variational Autoencoders(VAEs), and flow-based generative networks are doing well as generative models. Then the diffusion models had been developed with a more complex approach with high generating power and dealt with the limitations of other generative models. Diffusion models are widely used in deep learning.
Although the diffusion model is not a super powerful method but a good approach to generative models with the following criteria.
The diffusion model has the ability to generate more high-quality samples than GANs, VAEs, and flow-based generative models. Diffusion models can produce high-quality realistic images with textures.
This model can cover the modes of the data distribution more effectively, which means it can learn a set of diversity from data without overfitting a particular mode.
Diffusion models are more stable in training and less sensitive in hyperparameters.
No need for an explicit latent space in the model like VAEs.
These are the benefits of using diffusion models over other generative models. But this model also has limitations. It is slower in the sampling process and requires the reverse running diffusion process over multiple time steps for generating samples which can be computationally expensive.
The Architecture of the Diffusion Model
A denoising diffusion model adds the gaussian noise iteratively until the data becomes all noise. Then the reconstruction or reverse process is used to remove the noise iteratively and reconstruct the original data which becomes sharper than before. Before we have been told that the diffusion models are inspired by non-equilibrium thermodynamics where the models define a Markov chain of diffusion steps to add the noise to data slowly and then learn to reverse the diffusion process to reconstruct the original data from the noise. In other words, diffusion models destroy the input data through successive addition of gaussian noise iteratively and then learn to reconstruct the data from noise by reversing this noising process.
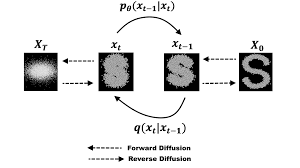
In the diffusion models, the generated images can be conditionally or unconditionally.
Unconditional means the model converts the noise into a random representative sample and the generation process is not controlled and the model can generate any images of any nature.
In the conditional data generation process, additional information (text or class labels) are provided in the model. So, the model can be controlled and generate a set of desired images.
Today we will go through the unconditional Image generation process of diffusion models.
Generally the diffusion model is a combination of two processes. They are:
Forward Diffusion
It destroys the training data through successive addition of gaussian noise. In the forward part, the diffusion model maps latent space from input data using a Markov chain.

Markov chain is a stochastic process that describes the sequences of possible events at each time step depending on only the events of the previous time step. So, in the diffusion model, the chain gradually adds noise to the data in order to gain the approximate posterior where the latent variables are the same dimension as the input data.
Parametrized Reverse
By reversing the noising process, the model learns to recover or reconstruct the data. After finishing the training process, we can generate new data by passing random noise samples through the learned denoising process.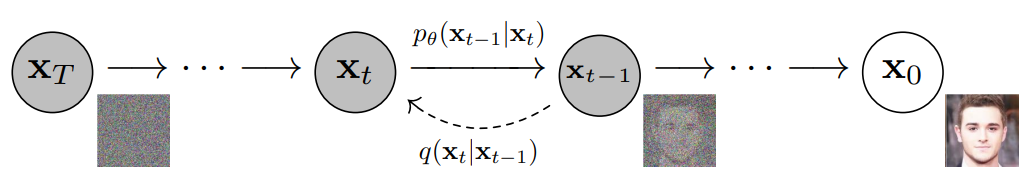
Working Process of Diffusion Model
The working process of diffusion models is discussed below-
The diffusion model uses the Markov chain process where the forward process requires a variance schedule to convert the image into isotropic gaussian noise in a specific timestamp.
The variance schedule is fixed that is used to learn the reverse process parameters so that the model can denoise the isotropic noise and generate more clear data.
Then an objective of the model is used to maximize the likelihood of the training data. KL divergence is used as a particular part of the loss function.
This is the training process of the diffusion model. In the “Denoising Diffusion Probabilistic Model”, they used a ‘linear scheduler’ instead of ‘a variance scheduler’. This means the noise is added to the data linearly at each timestep. Hope you get an overview of the structure of the diffusion model and the working process. Let’s implement the denoising diffusion model based on DDPM(Denoising Diffusion Probabilistic model) which is published in 2020 by Ho et al.
Implementation of Diffusion Model with Pytorch
First, import the packages, set up and installation part is done to implement the denoising diffusion model. Some packages such as einops is used for tensor manipulation, tqdm is for progress bar, einsum means Einstein summation convention. Other libraries are used for building layers, models, evaluations, and other utilities. You will get the code in Google Colab also.
from IPython.display import Image
!pip install -q -U einops datasets matplotlib tqdm
import math
from inspect import isfunction
from functools import partial
%matplotlib inline
import matplotlib.pyplot as plt
from tqdm.auto import tqdm
from einops import rearrange
import torch
from torch import nn, einsum
import torch.nn.functional as F
Helper functions
These function defines the utility functions and classes that will be used in neural network implementation. ‘exists’ function is to check if a value exists or not. The ‘Default’ function is to return the value if exists otherwise goes to the d function and returns the default value. The ‘Residual’ class is used to implement the residual connection in the model. The ‘Upsample’ function is used to increase the spatial dimensions of the tensor and the ‘Downsample’ is used to reduce the spatial dimensions of the tensors.
def exists(x):
return x is not None
def default(val, d):
if exists(val):
return val
return d() if isfunction(d) else d
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, *args, **kwargs):
return self.fn(x, *args, **kwargs) + x
def Upsample(dim):
return nn.ConvTranspose2d(dim, dim, 4, 2, 1)
def Downsample(dim):
return nn.Conv2d(dim, dim, 4, 2, 1)
‘SinusoidalPositionEmbeddings’ is used to keep track of which time step it is on. The class takes the tensor size of (batch_size,1) and returns the tensor shape of (batch_size, dim) where dim is the dimensionality of the position embeddings. In other words, it is used to incorporate information about the noise schedule(the noise levels or steps in the forward/reverse diffusion process) in the model.
class SinusoidalPositionEmbeddings(nn.Module):
def __init__(self, dim):
super().__init__()
self.dim = dim
def forward(self, time):
device = time.device
half_dim = self.dim // 2
embeddings = math.log(10000) / (half_dim - 1)
embeddings = torch.exp(torch.arange(half_dim, device=device) * -embeddings)
embeddings = time[:, None] * embeddings[None, :]
embeddings = torch.cat((embeddings.sin(), embeddings.cos()), dim=-1)
return embeddings
The ‘Block’ class represents a basic building block that consists of a 2D Convolution Layer, A group normalization layer, scaled exponential Linear Unit(Silu) activation function. This block can be used as a component in denoising diffusion probabilistic Model(DDPM).
class Block(nn.Module):
def __init__(self, dim, dim_out, groups = 8):
super().__init__()
self.proj = nn.Conv2d(dim, dim_out, 3, padding = 1)
self.norm = nn.GroupNorm(groups, dim_out)
self.act = nn.SiLU()
def forward(self, x, scale_shift = None):
x = self.proj(x)
x = self.norm(x)
if exists(scale_shift):
scale, shift = scale_shift
x = x * (scale + 1) + shift
x = self.act(x)
return x
The ‘ResnetBlock’ represents the residual block which is a core component of ResNet Architecture. The residual connection helps the model learn more complex functions. The time embeddings can be used to condition the denoising function on the specific step in the diffusion process which allows the model to learn how to denoise at different stages of the process.
class ResnetBlock(nn.Module):
def __init__(self, dim, dim_out, *, time_emb_dim=None, groups=8):
super().__init__()
self.mlp = (
nn.Sequential(nn.SiLU(), nn.Linear(time_emb_dim, dim_out))
if exists(time_emb_dim)
else None
)
self.block1 = Block(dim, dim_out, groups=groups)
self.block2 = Block(dim_out, dim_out, groups=groups)
self.res_conv = nn.Conv2d(dim, dim_out, 1) if dim != dim_out else nn.Identity()
def forward(self, x, time_emb=None):
h = self.block1(x)
if exists(self.mlp) and exists(time_emb):
time_emb = self.mlp(time_emb)
h = rearrange(time_emb, "b c -> b c 1 1") + h
h = self.block2(h)
return h + self.res_conv(x)
The ConvNextBlock class represents the convolutional neural Network block with some additional modification. Here most of the parameters are used for convolutional neural networks except the time embeddings method which represents the dimensionality of the time embeddings.
class ConvNextBlock(nn.Module):
def __init__(self, dim, dim_out, *, time_emb_dim=None, mult=2, norm=True):
super().__init__()
self.mlp = (
nn.Sequential(nn.GELU(), nn.Linear(time_emb_dim, dim))
if exists(time_emb_dim)
else None
)
self.ds_conv = nn.Conv2d(dim, dim, 7, padding=3, groups=dim)
self.net = nn.Sequential(
nn.GroupNorm(1, dim) if norm else nn.Identity(),
nn.Conv2d(dim, dim_out * mult, 3, padding=1),
nn.GELU(),
nn.GroupNorm(1, dim_out * mult),
nn.Conv2d(dim_out * mult, dim_out, 3, padding=1),
)
self.res_conv = nn.Conv2d(dim, dim_out, 1) if dim != dim_out else nn.Identity()
def forward(self, x, time_emb=None):
h = self.ds_conv(x)
if exists(self.mlp) and exists(time_emb):
condition = self.mlp(time_emb)
h = h + rearrange(condition, "b c -> b c 1 1")
h = self.net(h)
return h + self.res_conv(x)
The ‘Attention’ class is a PyTorch-based neural network that represents a self-attention module(a multi-head self-attention mechanism). This class is integrated to capture long-range dependencies and improve the reconstruction process. This architecture helps the model learn more complex patterns and relations in the data. This attention class may lead to better reconstruction.
class Attention(nn.Module):
def __init__(self, dim, heads=4, dim_head=32):
super().__init__()
self.scale = dim_head**-0.5
self.heads = heads
hidden_dim = dim_head * heads
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
self.to_out = nn.Conv2d(hidden_dim, dim, 1)
def forward(self, x):
b, c, h, w = x.shape
qkv = self.to_qkv(x).chunk(3, dim=1)
q, k, v = map(
lambda t: rearrange(t, "b (h c) x y -> b h c (x y)", h=self.heads), qkv
)
q = q * self.scale
sim = einsum("b h d i, b h d j -> b h i j", q, k)
sim = sim - sim.amax(dim=-1, keepdim=True).detach()
attn = sim.softmax(dim=-1)
out = einsum("b h i j, b h d j -> b h i d", attn, v)
out = rearrange(out, "b h (x y) d -> b (h d) x y", x=h, y=w)
return self.to_out(out)
The LinearAttention class is a PyTorch-based neural network that represents a linear self-attention module that is a more memory-efficient version of the multi-head self-attention mechanism. This class is used to capture the long-range dependencies and help the model to learn more complex patterns and representations in the data.
class LinearAttention(nn.Module):
def __init__(self, dim, heads=4, dim_head=32):
super().__init__()
self.scale = dim_head**-0.5
self.heads = heads
hidden_dim = dim_head * heads
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
self.to_out = nn.Sequential(nn.Conv2d(hidden_dim, dim, 1),
nn.GroupNorm(1, dim))
def forward(self, x):
b, c, h, w = x.shape
qkv = self.to_qkv(x).chunk(3, dim=1)
q, k, v = map(
lambda t: rearrange(t, "b (h c) x y -> b h c (x y)", h=self.heads), qkv
)
q = q.softmax(dim=-2)
k = k.softmax(dim=-1)
q = q * self.scale
context = torch.einsum("b h d n, b h e n -> b h d e", k, v)
out = torch.einsum("b h d e, b h d n -> b h e n", context, q)
out = rearrange(out, "b h c (x y) -> b (h c) x y", h=self.heads, x=h, y=w)
return self.to_out(out)
The PreNorm class is used to normalization an input tensor. Here GroupNormalization technique is used on the input tensor. Then the output after normalization is used in another function called fn and returns the value.
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn
self.norm = nn.GroupNorm(1, dim)
def forward(self, x):
x = self.norm(x)
return self.fn(x)
The Unet Class is a PyTorch-based neural network that is generally used in image segmentation tasks. In the diffusion model, This class can be used as a denoising score-matching network that learns to estimate the score function of the data distribution. This score function is used to guide the diffusion process toward generating realistic samples. Here the network takes the noisy image and progressively denoises it throughout the denoise process.
class Unet(nn.Module):
def __init__(
self,
dim,
init_dim=None,
out_dim=None,
dim_mults=(1, 2, 4, 8),
channels=3,
with_time_emb=True,
resnet_block_groups=8,
use_convnext=True,
convnext_mult=2,
):
super().__init__()
# determine dimensions
self.channels = channels
init_dim = default(init_dim, dim // 3 * 2)
self.init_conv = nn.Conv2d(channels, init_dim, 7, padding=3)
dims = [init_dim, *map(lambda m: dim * m, dim_mults)]
in_out = list(zip(dims[:-1], dims[1:]))
if use_convnext:
block_klass = partial(ConvNextBlock, mult=convnext_mult)
else:
block_klass = partial(ResnetBlock, groups=resnet_block_groups)
# time embeddings
if with_time_emb:
time_dim = dim * 4
self.time_mlp = nn.Sequential(
SinusoidalPositionEmbeddings(dim),
nn.Linear(dim, time_dim),
nn.GELU(),
nn.Linear(time_dim, time_dim),
)
else:
time_dim = None
self.time_mlp = None
# layers
self.downs = nn.ModuleList([])
self.ups = nn.ModuleList([])
num_resolutions = len(in_out)
for ind, (dim_in, dim_out) in enumerate(in_out):
is_last = ind >= (num_resolutions - 1)
self.downs.append(
nn.ModuleList(
[
block_klass(dim_in, dim_out, time_emb_dim=time_dim),
block_klass(dim_out, dim_out, time_emb_dim=time_dim),
Residual(PreNorm(dim_out, LinearAttention(dim_out))),
Downsample(dim_out) if not is_last else nn.Identity(),
]
)
)
mid_dim = dims[-1]
self.mid_block1 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)
self.mid_attn = Residual(PreNorm(mid_dim, Attention(mid_dim)))
self.mid_block2 = block_klass(mid_dim, mid_dim, time_emb_dim=time_dim)
for ind, (dim_in, dim_out) in enumerate(reversed(in_out[1:])):
is_last = ind >= (num_resolutions - 1)
self.ups.append(
nn.ModuleList(
[
block_klass(dim_out * 2, dim_in, time_emb_dim=time_dim),
block_klass(dim_in, dim_in, time_emb_dim=time_dim),
Residual(PreNorm(dim_in, LinearAttention(dim_in))),
Upsample(dim_in) if not is_last else nn.Identity(),
]
)
)
out_dim = default(out_dim, channels)
self.final_conv = nn.Sequential(
block_klass(dim, dim), nn.Conv2d(dim, out_dim, 1)
)
def forward(self, x, time):
x = self.init_conv(x)
t = self.time_mlp(time) if exists(self.time_mlp) else None
h = []
# downsample
for block1, block2, attn, downsample in self.downs:
x = block1(x, t)
x = block2(x, t)
x = attn(x)
h.append(x)
x = downsample(x)
# bottleneck
x = self.mid_block1(x, t)
x = self.mid_attn(x)
x = self.mid_block2(x, t)
# upsample
for block1, block2, attn, upsample in self.ups:
x = torch.cat((x, h.pop()), dim=1)
x = block1(x, t)
x = block2(x, t)
x = attn(x)
x = upsample(x)
return self.final_conv(x)
The beta schedule functions determine the noise schedule which is important for controlling the noise that is added or removed at each step of the diffusion process. These functions are used to give the number of time steps in the diffusion process. In other words, These functions provide a sequence of beta values that dictate how the noise is applied during the forward and reverse diffusion process.
The cosine_beta_schedule generates the cosine-based beta schedule where parameter s controls the shape of the cosine curve.
The linear_beta_schedule generates the linear beta schedule for the given time steps that returns the linearly spaced tensor between the beta start and beta ends.
The quadratic_beta_schedule generates the quadratic beta schedule that calculates a quadratic curve by taking the square of the linearly spaced tensor between the square roots of the start and the ends.
The sigmoid_beta_schedule generates the sigmoid-based data schedule for the given time steps. It calculates the sigmoid function of the linearly spaced tensor between -6,6.
Overall, the beta schedule functions are used to create different noise schedules for the forward and reverse diffusion processes. The choice of the beta schedule can impact the performance and convergence of the diffusion models.
def cosine_beta_schedule(timesteps, s=0.008):
steps = timesteps + 1
x = torch.linspace(0, timesteps, steps)
alphas_cumprod = torch.cos(((x / timesteps) + s) / (1 + s) * torch.pi * 0.5) ** 2
alphas_cumprod = alphas_cumprod / alphas_cumprod[0]
betas = 1 - (alphas_cumprod[1:] / alphas_cumprod[:-1])
return torch.clip(betas, 0.0001, 0.9999)
def linear_beta_schedule(timesteps):
beta_start = 0.0001
beta_end = 0.02
return torch.linspace(beta_start, beta_end, timesteps)
def quadratic_beta_schedule(timesteps):
beta_start = 0.0001
beta_end = 0.02
return torch.linspace(beta_start**0.5, beta_end**0.5, timesteps) ** 2
def sigmoid_beta_schedule(timesteps):
beta_start = 0.0001
beta_end = 0.02
betas = torch.linspace(-6, 6, timesteps)
return torch.sigmoid(betas) * (beta_end - beta_start) + beta_start
Here the code specifies the number of timesteps and calculates the beta schedule using the linear_beta_schedule function. Then alphas are computed that is complementary values of betas and the cumulative product of alphas has computed. Then it pads the cumulative product of alphas with an extra value of 1 at the beginning. Then the square root of reciprocal alphas is also calculated. Then for the diffusion process, the square root of the cumulative product of alphas and the square root of 1 minus cumulative product has computed. Then for the posterior distribution, the code calculates the posterior_variance which is used to determine how the posterior distribution evolves during the reverse diffusion process. At last, the extract function gathers the values in the input tensor corresponding to the specific indices and reshapes the output to match the input tensor shape. This function is useful for extracting the specific values from tensors that contain various statistics during the diffusion process.
timesteps = 200Let'e test out the model-
# define beta schedule
betas = linear_beta_schedule(timesteps=timesteps)
# define alphas
alphas = 1. - betas
alphas_cumprod = torch.cumprod(alphas, axis=0)
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value=1.0)
sqrt_recip_alphas = torch.sqrt(1.0 / alphas)
# calculations for diffusion q(x_t | x_{t-1}) and others
sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)
sqrt_one_minus_alphas_cumprod = torch.sqrt(1. - alphas_cumprod)
# calculations for posterior q(x_{t-1} | x_t, x_0)
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)
def extract(a, t, x_shape):
batch_size = t.shape[0]
out = a.gather(-1, t.cpu())
return out.reshape(batch_size, *((1,) * (len(x_shape) - 1))).to(t.device)
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
image

Preprocess the Image
‘Torchvision.transforms’ defines a series of transformation functions. Here resizing, center cropping, covert the image into tensor datatype, and scaling from (0,1) to (-1,1) by lambda function are done as transform variables. Then the reverse_transform does the inverse of the previously defined transformation.
from torchvision.transforms import Compose, ToTensor, Lambda, ToPILImage, CenterCrop, Resize
import numpy as np
image_size = 128
transform = Compose([
Resize(image_size),
CenterCrop(image_size),
ToTensor(), # turn into Numpy array of shape HWC, divide by 255
Lambda(lambda t: (t * 2) - 1),
])
x_start = transform(image).unsqueeze(0)
print(x_start.shape)
torch.Size([1, 3, 128, 128])
reverse_transform = Compose([
Lambda(lambda t: (t + 1) / 2),
Lambda(lambda t: t.permute(1, 2, 0)), # CHW to HWC
Lambda(lambda t: t * 255.),
Lambda(lambda t: t.numpy().astype(np.uint8)),
ToPILImage(),
])
reverse_transform(x_start.squeeze())

The following code indicates how to generate a noisy image from a staring image at a specific time step. In the forward diffusion process, the noise is added to the starting image. The ‘q_sample’ function calculates the noisy image by multiplying the square root of the cumulative product of Alphas with the staring image and adding the product of the square root of one minus the cumulative product of alphas with the noise. The ‘get_noisy_image’ takes the starting image and a timestep, then generates the noisy image by the q_sample function and converts the noisy image into a Pillow image.
Below We take a time step of 40 and a starting image and generate the noisy image and visualize that.
# forward diffusion (using the nice property)
def q_sample(x_start, t, noise=None):
if noise is None:
noise = torch.randn_like(x_start)
sqrt_alphas_cumprod_t = extract(sqrt_alphas_cumprod, t, x_start.shape)
sqrt_one_minus_alphas_cumprod_t = extract(
sqrt_one_minus_alphas_cumprod, t, x_start.shape
)
return sqrt_alphas_cumprod_t * x_start + sqrt_one_minus_alphas_cumprod_t * noise
def get_noisy_image(x_start, t):
# add noise x_noisy = q_sample(x_start, t=t)
# turn back into PIL image noisy_image = reverse_transform(x_noisy.squeeze()) return noisy_image # take time step t = torch.tensor([40])
get_noisy_image(x_start, t)

The following code represents how to visualize the noisy images generated at different time steps using the diffusion process. The more time steps add more noise to the input data and generate more noisy images.
import matplotlib.pyplot as plt
torch.manual_seed(0)
def plot(imgs, with_orig=False, row_title=None, **imshow_kwargs):
if not isinstance(imgs[0], list):
# Make a 2d grid even if there's just 1 row
imgs = [imgs]
num_rows = len(imgs)
num_cols = len(imgs[0]) + with_orig
fig, axs = plt.subplots(figsize=(200,200), nrows=num_rows, ncols=num_cols, squeeze=False)
for row_idx, row in enumerate(imgs):
row = [image] + row if with_orig else row
for col_idx, img in enumerate(row):
ax = axs[row_idx, col_idx]
ax.imshow(np.asarray(img), **imshow_kwargs)
ax.set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])
if with_orig:
axs[0, 0].set(title='Original image')
axs[0, 0].title.set_size(8)
if row_title is not None:
for row_idx in range(num_rows):
axs[row_idx, 0].set(ylabel=row_title[row_idx])
plt.tight_layout()
plot([get_noisy_image(x_start, torch.tensor([t])) for t in [0, 50, 100, 150, 199]])

The ‘p_losses’ function calculates the loss between the true noise and predicted noise in the diffusion noise which is used to train the denoising model. There are 3 types of losses used such as L1 loss, L2 loss, and Huber Loss.
def p_losses(denoise_model, x_start, t, noise=None, loss_type="l1"):
if noise is None:
noise = torch.randn_like(x_start)
x_noisy = q_sample(x_start=x_start, t=t, noise=noise)
predicted_noise = denoise_model(x_noisy, t)
if loss_type == 'l1':
loss = F.l1_loss(noise, predicted_noise)
elif loss_type == 'l2':
loss = F.mse_loss(noise, predicted_noise)
elif loss_type == "huber":
loss = F.smooth_l1_loss(noise, predicted_noise)
else:
raise NotImplementedError()
return loss
To train the model, the fashion mnist dataset is used. Some data transformation is used such as random horizontal flipping, converting image into Tensor, and normalization of pixel values into (-1,1). Then to load the data efficiently and batch the data, the dataloader function is used. Mainly this part prepares the data to train the model.
from datasets import load_dataset
dataset = load_dataset("fashion_mnist")
image_size = 28
channels = 1
batch_size = 128
from torchvision import transforms
from torch.utils.data import DataLoader
# define image transformations (e.g. using torchvision)
transform = Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Lambda(lambda t: (t * 2) - 1)
])
# define function
def transforms(examples):
examples["pixel_values"] = [transform(image.convert("L")) for image in examples["image"]]
del examples["image"]
return examples
transformed_dataset = dataset.with_transform(transforms).remove_columns("label")
# create dataloader
dataloader = DataLoader(transformed_dataset["train"], batch_size=batch_size, shuffle=True)
batch = next(iter(dataloader))
print(batch.keys())
The p_sample function is used to sample from the reverse process of the diffusion model which helps to generate denoised images from noisy images using a trained denoising model. This function takes the denoise model, a noisy image, a time step, and a time index. Then returns a denoised image.
@torch.no_grad()
def p_sample(model, x, t, t_index):
betas_t = extract(betas, t, x.shape)
sqrt_one_minus_alphas_cumprod_t = extract(
sqrt_one_minus_alphas_cumprod, t, x.shape
)
sqrt_recip_alphas_t = extract(sqrt_recip_alphas, t, x.shape)
# Equation 11 in the paper
# Use our model (noise predictor) to predict the mean
model_mean = sqrt_recip_alphas_t * (
x - betas_t * model(x, t) / sqrt_one_minus_alphas_cumprod_t
)
if t_index == 0:
return model_mean
else:
posterior_variance_t = extract(posterior_variance, t, x.shape)
noise = torch.randn_like(x)
# Algorithm 2 line 4:
return model_mean + torch.sqrt(posterior_variance_t) * noise
Here the ‘p_sample_loop’ function is responsible for sample images from the denoising process of the diffusion model at all the time steps. This function takes the trained denoising model and the shape of the output images. Then returns a list of images generated at each time step throughout the reverse process.
Then the ‘sample’ function makes the p_sample_function more convenient to use for generating images using the diffusion model. The function takes denoising models, image size, batch size, and the number of channels. Then generate and returns a list of denoised images at all time steps throughout the reverse process.
# Algorithm 2 (including returning all images)
@torch.no_grad()
def p_sample_loop(model, shape):
device = next(model.parameters()).device
b = shape[0]
# start from pure noise (for each example in the batch)
img = torch.randn(shape, device=device)
imgs = []
for i in tqdm(reversed(range(0, timesteps)), desc='sampling loop time step', total=timesteps):
img = p_sample(model, img, torch.full((b,), i, device=device, dtype=torch.long), i)
imgs.append(img.cpu().numpy())
return imgs
@torch.no_grad()
def sample(model, image_size, batch_size=16, channels=3):
return p_sample_loop(model, shape=(batch_size, channels, image_size, image_size))
The following part is used to save the denoised model in the directory and a utility function named num_to_groups for further use in the model.
from pathlib import Path
def num_to_groups(num, divisor):
groups = num // divisor remainder = num % divisor arr = [divisor] * groups if remainder > 0: arr.append(remainder) return arr
results_folder = Path("./results")
results_folder.mkdir(exist_ok = True)
save_and_sample_every = 1000
This part is used to set up the optimizers used in the model and create an instance of the Unet model to train and also specify the device for computation.
from torch.optim import Adam
device = "cuda" if torch.cuda.is_available() else "cpu"
model = Unet(
dim=image_size,
channels=channels,
dim_mults=(1, 2, 4,)
)
model.to(device)
optimizer = Adam(model.parameters(), lr=1e-3)
The following code indicates the main training loop for the diffusion model using the U-net denoising model. The model is trained on UNet architecture as the denoising model, then calculates the loss at each level, then updates the model parameters, and periodically generates and saves a set of images during training.
from torchvision.utils import save_image
epochs = 5
for epoch in range(epochs):
for step, batch in enumerate(dataloader):
optimizer.zero_grad()
batch_size = batch["pixel_values"].shape[0]
batch = batch["pixel_values"].to(device)
t = torch.randint(0, timesteps, (batch_size,), device=device).long()
loss = p_losses(model, batch, t, loss_type="huber")
if step % 100 == 0:
print("Loss:", loss.item())
loss.backward()
optimizer.step()
# save generated images
if step != 0 and step % save_and_sample_every == 0:
milestone = step // save_and_sample_every
batches = num_to_groups(4, batch_size)
all_images_list = list(map(lambda n: sample(model, batch_size=n, channels=channels), batches))
all_images = torch.cat(all_images_list, dim=0)
all_images = (all_images + 1) * 0.5
save_image(all_images, str(results_folder / f'sample-{milestone}.png'), nrow = 6)
Our training part is finished. Now we can generate a new sample from the trained denoising model. Here the following code is used for generating and displaying a sample image from the trained diffusion model. The code generates a set of images and then displays a randomly chosen image from the generated samples. The generated image sample is displayed which looks like a shoe.
# sample 64 images samples = sample(model, image_size=image_size, batch_size=64, channels=channels)
# show a random one random_index = 5
plt.imshow(samples[-1][random_index].reshape(image_size, image_size, channels), cmap="gray")

Now we will see a GIF file that indicates how an image is generated from the noisy image. The following code is responsible for creating and saving an animated GIF of the diffusion process for a randomly chosen image. Mainly the code allows you to visualize how the diffusion model generates images over time.
import matplotlib.animation as animation
random_index = 53
fig = plt.figure()
ims = []
for i in range(timesteps):
im = plt.imshow(samples[i][random_index].reshape(image_size, image_size, channels), cmap="gray", animated=True)
ims.append([im])
animate = animation.ArtistAnimation(fig, ims, interval=50, blit=True, repeat_delay=1000)
animate.save('diffusion.gif')
plt.show()

Great. We have created the model, trained and then generate samples. Basically, the diffusion model takes a large time step and huge time and also it is computationally expensive. So, our generated images are not so clear. Now we will talk about the pre-trained diffusion model that generates a more clear and sharper image and also we can use that model to generate images as our desired dataset.
Pretrained Denoising Diffusion Model
First, install and import the denoising_diffusion_pytorch package. Here Unet defines the UNet architecture for denoising images. Gaussian Diffusion is for gaussian diffusion process. An instance named model is created of Unet model where dim indicates the number of feature maps before the first downsampling and dim_mults gives multiplicands for this value and successive downsampling.
!pip install denoising_diffusion_pytorch
import torch
from denoising_diffusion_pytorch import Unet,GaussianDiffusion
model = Unet(
dim = 64,
dim_mults = (1, 2, 4, 8)
)
The network architecture has been defined, so now need to define the diffusion model so that we can pass the unet model with several parameters such as a number of images to generate, the number of timesteps in the diffusion process, and a choice of loss type.
diffusion = GaussianDiffusion(
model,
image_size = 128,
timesteps = 1000, # number of steps
loss_type = 'l1' # L1 or L2
)
Our diffusion model is defined, now train the model. First, we generate some random data and train on the diffusion model.
training_images = torch.randn(8, 3, 128, 128)
loss = diffusion(training_images)
loss.backward()
Our model has trained and then we generate some random images. We trained on the noise image. Now train the model with the custom dataset.
sampled_images = diffusion.sample(batch_size = 4)

Train Diffusion model on Custom data
Now we will train the model with the custom dataset. The denoising_diffusion_pytorch package provides a trainer function to train with custom data. In the ‘path/in/your/images’, you have to specify the path of the image folder. One thing that is notable is that you have to train the model in cuda enabled device. After training on MNIST images, we get sharper and more clear generated images. See the GIF of the generated image.from denoising_diffusion_pytorch import Unet, GaussianDiffusion, Trainer model = Unet( dim = 64, dim_mults = (1, 2, 4, 8) ).cuda() diffusion = GaussianDiffusion( model, image_size = 128, timesteps = 1000, # number of steps loss_type = 'l1' # L1 or L2 ).cuda() trainer = Trainer( diffusion, ‘path/to/your/images’, train_batch_size = 32, train_lr = 2e-5, train_num_steps = 700000, # total training steps gradient_accumulate_every = 2, # gradient accumulation steps ema_decay = 0.995, # exponential moving average decay amp = True # turn on mixed precision ) trainer.train()

Applications of Diffusion Model
The denoising diffusion probabilistic model has shown promising results in various applications, especially in generative modeling. Some popular applications of diffusion models are given below.
- Anomaly detection: It can be used to detect anomalies or outliers by measuring the reconstruction error during the denoising process.
- Image to Image translation: It can be used to translate one type of image to another type of image such as a semantic image to a realistic image.
- Image inpainting: It can be used to fill the missing parts of an image or corrupted parts of the image. It has the ability to effectively denoise and reconstruct the missing parts. It can also be a replacement for unwanted objects from images by another object.
- Text to Image: With the help of this model, we can convert the text to the associated images.
- Super-resolution: Diffusion models can be used to upgrade the resolution of low-quality images. The diffusion models iteratively refine and sharpen the details of the image.
- Text to Videos: With the help of text prompts, the diffusion model can generate the sequence of videos.
- Image Outpainting: It is a process where the diffusion model adds details outside or beyond the original image. By utilizing the parts of the original images, we can extend the original images.
- Style transfer: The diffusion model has the ability to perform style transfer tasks. Here the goal is to transfer the style from one image to another as well as preserve the content of the image.
- Data Denoising: For denoising tasks, it can be applied to various data types such as text, audio, and images. As a diffusion process, the model can effectively remove noise and reconstruct clean data samples.
- Speech Synthesis: It can use to generate speech signals with realistic prosody, pitch, and timber. It can generate high-quality audio samples and is also used to remove noise from audio.
- Molecular Generation: The generative models play a vital role in drug discovery and molecular generation. Diffusion models also perform well in this perspective.
The diffusion model is based on the diffusion process which is a series of steps where noise is gradually added to the original data points and the denoising functions aim to remove the noise and reconstruct the original data. Like, we discussed the basics of the diffusion model, the architecture, and the procedure of the model and then learned the implementation of the diffusion model. Hope you create the base of the diffusion model and understand the working procedure of the diffusion model. Now you can try to implement the other applications of the diffusion model such as inpainting, outpainting, super-resolution, guided generation, infinite zooming, and so on. Some other steps can be taken, those are given below.
Conclusion
You can research to improve the efficiency of the diffusion model architecture such as speeding up the training process and reducing the number of steps of the diffusion model. You can understand the diffusion process more deeply so that you can generate better-quality samples.
Hope you get some ideas and the tutorial is beneficial to you. Thanks for reading the tutorial and enjoy the deep learning field.