- An Introduction to Machine Learning | The Complete Guide
- Data Preprocessing for Machine Learning | Apply All the Steps in Python
- Regression
- Learn Simple Linear Regression in the Hard Way(with Python Code)
- Multiple Linear Regression in Python (The Ultimate Guide)
- Polynomial Regression in Two Minutes (with Python Code)
- Support Vector Regression Made Easy(with Python Code)
- Decision Tree Regression Made Easy (with Python Code)
- Random Forest Regression in 4 Steps(with Python Code)
- 4 Best Metrics for Evaluating Regression Model Performance
- Classification
- A Beginners Guide to Logistic Regression(with Example Python Code)
- K-Nearest Neighbor in 4 Steps(Code with Python & R)
- Support Vector Machine(SVM) Made Easy with Python
- Kernel SVM for Dummies(with Python Code)
- Naive Bayes Classification Just in 3 Steps(with Python Code)
- Decision Tree Classification for Dummies(with Python Code)
- Random forest Classification
- Evaluating Classification Model performance
- A Simple Explanation of K-means Clustering in Python
- Hierarchical Clustering
- Association Rule Learning | Apriori
- Eclat Intuition
- Reinforcement Learning in Machine Learning
- Upper Confidence Bound (UCB) Algorithm: Solving the Multi-Armed Bandit Problem
- Thompson Sampling Intuition
- Artificial Neural Networks
- Natural Language Processing
- Deep Learning
- Principal Component Analysis
- Linear Discriminant Analysis (LDA)
- Kernel PCA
- Model Selection & Boosting
- K-fold Cross Validation in Python | Master this State of the Art Model Evaluation Technique
- XGBoost
- Convolution Neural Network
- Dimensionality Reduction
Regression | Machine Learning
Regression: Basically, Regression is a statistical approach to find the correlations between variables(dependent and independent).
In the context of machine learning, Regression is an algorithm or technique that is applied to a certain dataset to find the correlation between the independent and dependent variables and with that, predicts the outcome of an unknown value.
For example, if you have a dataset that contains the salary of a certain number of employees according to their experience, your model will find the correlation between the experience and salary from that dataset. And with that correlation, it predicts the unknown salary of employees from their experience.
How Does It Work?
Let's take an example of a regression task. Assume that we have a dataset that contains the price(in dollars) of houses according to their area(in meter squared) of the town Branalle. The plot for price vs area data of the town Branalle is depicted below:
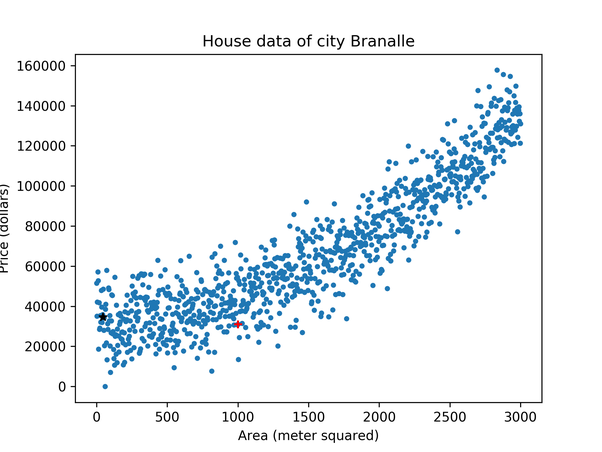
Here the value of area on the X-axis is the independent variable, and on the Y-axis, the value of the price is the dependent variable.
Now if we build a regression model based on this data, our model will try to find the correlation between the area and the price. And from that correlation, the outcome of the model will be a simple line(linear or nonlinear based on the chosen algorithm) on the graph. The line will be the prediction line of the model, upon which it will predict the unknown price according to the given area of a house.
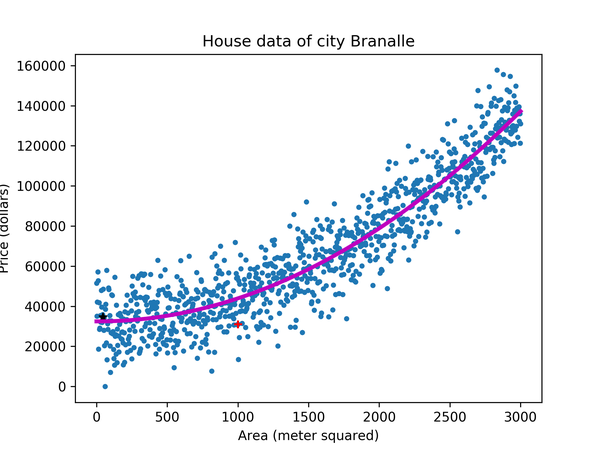
Here the line is the prediction line constructed by the regression model. This prediction line will be used as a reference to predict an unknown value, that is the price of a house.
How to Understand a Regression Task?
Regression algorithms give you a continuous output. That means if you are asked to build a model that predicts the future outcome where the output will be continuous. Then you must choose one of the Regression algorithms to build your model.
For example, if you are provided with a dataset about houses, and asked to predict their prices, that is a regression task because the price will be a continuous output.
Classification of Regression:
There are several types of Regression models. They are as follows:
In the following articles, we will understand these models in detail and learn how to implement them in Python.