- Getting Started with Generative Artificial Intelligence
- Mastering Image Generation Techniques with Generative Models
- Generating Art with Neural Style Transfer
- Exploring Deep Dream and Neural Style Transfer
- A Guide to 3D Object Generation with Generative Models
- Text Generation with Generative Models
- Language Generation Models for Prompt Generation
- Chatbots with Generative AI Models
- Music Generation with Generative Models
- A Beginner’s Guide to Generative Design
- Video Generation with Generative Models
- Anime Generation with Generative Models
- Generative Adversarial Networks (GANs)
- Generative modeling using Variational AutoEncoders
- Reinforcement Learning for Generation
- Interactive Generative Systems
- Fashion Generation with Generative Models
- Story Generation with Generative Models
- Character Generation with Generative AI
- Generative Modeling for Simulation
- Data Augmentation Techniques with Generative Models
- Future Directions in Generative AI
A Guide to 3D Object Generation with Generative Models | Generative AI

Introduction
OpenAI developed the open-source text-to-3D model ShapeE. This lesson looks at how it turns simple text prompts into detailed 3D objects and makes neural radiation fields for realistic rendering. It shows images of 3D objects and compares ShapeE and PointE.
Importance of 3D Object Generation
3D object generation is important in many fields, such as learning, architecture, and games. It makes it possible for simulations to be accurate, experiences to be immersive, and quick prototyping to occur. Designers can see how ideas will look, architects can plan spaces, and engineers can test models by making 3D things digitally. It's necessary for creativity, innovation, and useful answers in many areas.
Let's dive into these 3D Object Generation
- Generate 3D Objects from Text with Shap-E
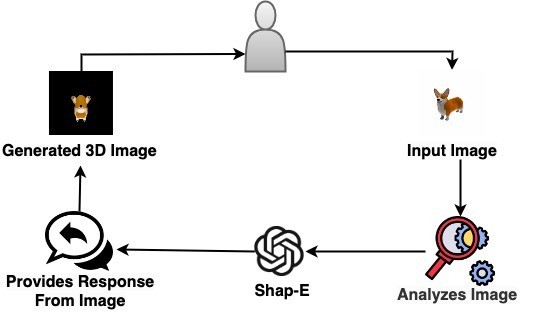
- Generate 3D Objects from Images with Shap-E
Overview Shape-E: Bridging Text and Images for 3D Object Generation
ShapeE is a conditional generative model for 3D assets, generating implicit functions parameters directly. It integrates with Blender, making it accessible to professionals and enthusiasts.
The Workflow:
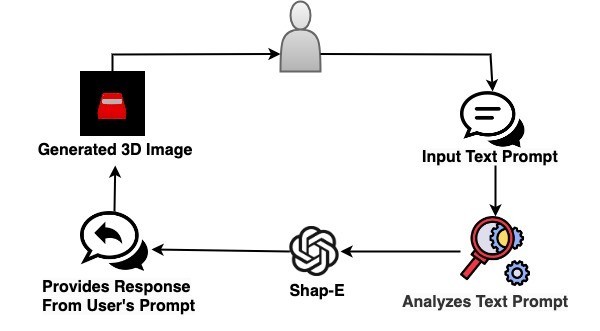
Generate 3D Objects from Text
Generate 3D Objects from Text
Implementation of 3D Object Generation Using Shap-EGenerate 3D Objects from Text Using Shap-E
Let's go through a simple code to understand things better:
Step 1: Installing Dependencies
!git clone https://github.com/openai/shap-e%cd shap-e
!pip install -e .
Step 2: Importing the Necessary Libraries
import torchfrom shap_e.diffusion.sample import sample_latents
from shap_e.diffusion.gaussian_diffusion import diffusion_from_config
from shap_e.models.download import load_model, load_config
from shap_e.util.notebooks import create_pan_cameras, decode_latent_images, gif_widget
Step 3: Adaptive Model Loading for Text and Diffusion Tasks
This code segment loads models for text generation and diffusion, utilizing either GPU or CPU based on availability.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')xm = load_model('transmitter', device=device)
model = load_model('text300M', device=device)
diffusion = diffusion_from_config(load_config('diffusion'))
Step 4: Input Prompt
batch_size = 4guidance_scale = 15.0
prompt = "a car"
Step 5: Text-Guided Latent Sampling for Image Generation
This code uses a diffusion model to create graphics from text inputs. It uses mixed precision and Karras-style sampling for efficiency, modifies batch size and guiding scale for control, refines images via several stages with progress updates.
latents = sample_latents(batch_size=batch_size,
model=model,
diffusion=diffusion,
guidance_scale=guidance_scale,
model_kwargs=dict(texts=[prompt] * batch_size),
progress=True,
clip_denoised=True,
use_fp16=True,
use_karras=True,
karras_steps=64,
sigma_min=1e-3,
sigma_max=160,
s_churn=0,
)
Step 6: Generating 3D Image
The code segment uses Neural Radiance Fields (NERF) or Scene-Transformer Fields (STF) rendering modes to create panoramic cameras for rendering images from latent vectors. The size of the images is determined by the variable size, with larger values causing longer rendering times. The loop iterates over each latent vector, decodes it, and displays the resulting images.
# you can change this to 'stf'render_mode = 'nerf'
# this is the size of the renders; higher values take longer to render.
size = 64
cameras = create_pan_cameras(size, device)
for i, latent in enumerate(latents):
images = decode_latent_images(xm, latent, cameras, rendering_mode=render_mode)
display(gif_widget(images))
Generated Output 3D Images:

Generate 3D Objects from Images Using Shap-E
Let’s go through a simple code to understand things better:
Step 1: Installing Dependencies
!git clone https://github.com/openai/shap-e%cd shap-e
!pip install -e .
Step 2: Importing the Necessary Libraries
import torchfrom shap_e.diffusion.sample import sample_latents
from shap_e.diffusion.gaussian_diffusion import diffusion_from_config
from shap_e.models.download import load_model, load_config
from shap_e.util.notebooks import create_pan_cameras, decode_latent_images, gif_widget
from shap_e.util.image_util import load_image
Step 3: Adaptive Model Loading for Text and Diffusion Tasks
This code segment loads models for text generation and diffusion, utilizing either GPU or CPU based on availability.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')xm = load_model('transmitter', device=device)
model = load_model('image300M', device=device)
diffusion = diffusion_from_config(load_config('diffusion'))
Step 4: Input Image
batch_size = 4guidance_scale = 3.0
image = load_image("/content/corgi.png")
Step 5: Image-Guided Latent Sampling for 3D Image Generation
This code efficiently generates latent vectors from a pre-trained model with image guidance. It utilizes a diffusion model, adjusting parameters for precision and processing steps. The resulting latent representations are tailored to input images, enabling various downstream tasks.
latents = sample_latents(batch_size=batch_size,
model=model,
diffusion=diffusion,
guidance_scale=guidance_scale,
model_kwargs=dict(images=[image] * batch_size),
progress=True,
clip_denoised=True,
use_fp16=True,
use_karras=True,
karras_steps=64,
sigma_min=1e-3,
sigma_max=160,
s_churn=0,
)
Step 6: Generating To 3D Image
The code segment creates 3D scenes using Neural Radiance Fields or Sliced Tree Fusion, sets the render size, creates panoramic cameras, decodes latent vectors into images, and displays the images using a GIF widget, enabling visualization of 3D scenes generated from latent representations.
# you can change this to 'stf' for mesh renderingrender_mode = 'nerf'
# this is the size of the renders; higher values take longer to render.
size = 64
cameras = create_pan_cameras(size, device)
for i, latent in enumerate(latents):
images = decode_latent_images(xm, latent, cameras, rendering_mode=render_mode)
display(gif_widget(images))
Generated Output 3D Images:

Conclusion
This tutorial explores 3D object generation using ShapeE, an OpenAI model. It showcases its ability to transform text prompts into intricate 3D objects and generate Neural Radiance Fields for realistic rendering. ShapeE is significant in industries like gaming, architecture, and education. The tutorial provides step-by-step guidance on generating 3D objects from text and images, emphasizing adaptive model loading and efficient latent sampling techniques.