- Getting Started with Generative Artificial Intelligence
- Mastering Image Generation Techniques with Generative Models
- Generating Art with Neural Style Transfer
- Exploring Deep Dream and Neural Style Transfer
- A Guide to 3D Object Generation with Generative Models
- Text Generation with Generative Models
- Language Generation Models for Prompt Generation
- Chatbots with Generative AI Models
- Music Generation with Generative Models
- A Beginner’s Guide to Generative Design
- Video Generation with Generative Models
- Anime Generation with Generative Models
- Generative Adversarial Networks (GANs)
- Generative modeling using Variational AutoEncoders
- Reinforcement Learning for Generation
- Interactive Generative Systems
- Fashion Generation with Generative Models
- Story Generation with Generative Models
- Character Generation with Generative AI
- Generative Modeling for Simulation
- Data Augmentation Techniques with Generative Models
- Future Directions in Generative AI
Language Generation Models for Prompt Generation | Generative AI
Introduction
Effective use of language generation models requires prompt generation. Language models like GPT have garnered a lot of interest because they can produce writing that appears to be human-written. This lesson will cover the significance of language models in prompt generation, explain the workflow, give examples of code implementation, and end with some thoughts on the possibilities of prompt generation.
Importance of Language Models
Language models are what make prompt generation work. These models have already been trained on huge amounts of text data and can, given a prompt, write text that makes sense and fits the situation. They can be used in a lot of different areas, like natural language processing, content creation, dialogue systems, and more. Using language models lets you automate tasks that include creating text, which saves time and resources while keeping quality and consistency.
Let’s dive into these Language Generation Models
- GPT-2
- GPT-Neo
- GPT-4
Overview of GPT-2, GPT-Neo & GPT-4
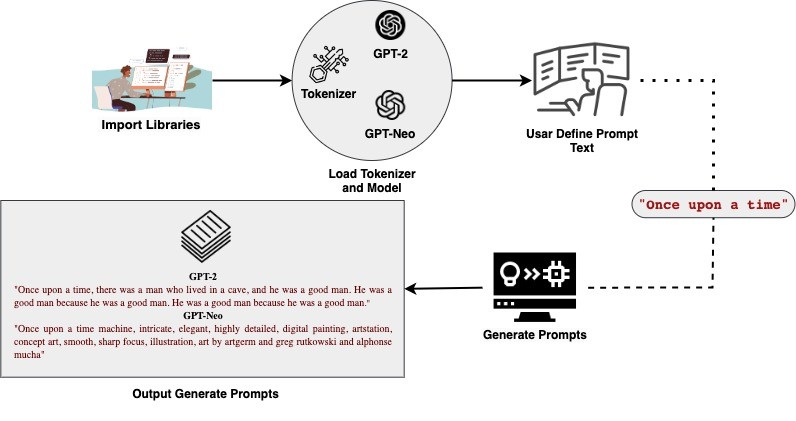
GPT-2: OpenAI created the Large Language model GPT-2. With text from books, articles, and websites, it has been trained on 8 million web pages. It comes in multiple variants, each with a varying number of parameters. 1.5 B parameters are found in the largest version.
GPT-Neo: EleutherAI's GPT-Neo is a free language model trained on the Pile dataset, resembling GPT-2. It uses local attention and 256 token window sizes. The model's parameters vary, with the largest version having 2.7 B specifications. Compared to OpenAI's proprietary GPT models, it's a strong substitute.
The Workflow of GPT-2 & GPT-Neo:
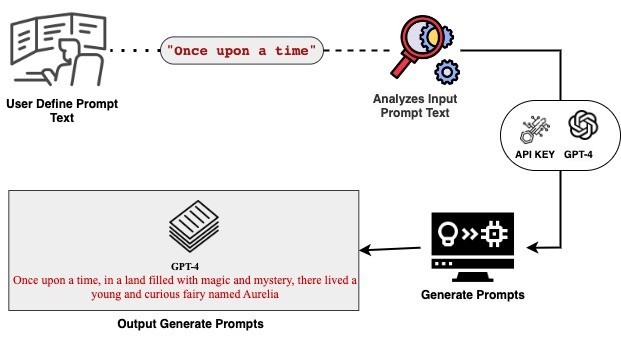
GPT-4: GPT-4's Arrival The most recent accomplishment of OpenAI, the release of GPT-4 in 2023, marks the timeline's conclusion. These models are the best of what is now possible in NLP, together with its contemporary models such as BingChat, Dolly 2.0, and StableLM.
The Workflow of GPT-4:
Implementation of Prompt Generation Using GPT-2
Let’s go through a simple code to understand things better:
Step 1: Utilizing GPT-2 for Text Generation via Hugging Face Pipeline
The code initializes a text generation pipeline using a GPT-2 model via Hugging Face. This streamlined approach simplifies text generation tasks, abstracting away model loading complexities. Users can easily generate text for various NLP tasks.
# Use a pipeline as a high-level helperfrom transformers import pipeline
pipe = pipeline("text-generation", model="Ar4ikov/gpt2-medium-stable-diffusion-prompt-generator")
Step 2: Load model
The code directly loads a GPT-2 model and tokenizer from Hugging Face's Transformers library. It allows immediate access to the model for text generation tasks, such as completion and dialogue systems.
# Load model directlyfrom transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Ar4ikov/gpt2-medium-stable-diffusion-prompt-generator")
model = AutoModelForCausalLM.from_pretrained("Ar4ikov/gpt2-medium-stable-diffusion-prompt-generator")
Step 3: GPT-2 Prompt Generation Function
The code defines a prompt generation function using a pre-trained GPT-2 model. It encodes input text, generates prompt continuations, and decodes the output for human readability. This facilitates efficient text prompt generation with GPT-2.
# Define prompt generation functiondef generate_prompt(prompt_text, max_length=50, num_return_sequences=1, temperature=1.0):
input_ids = tokenizer.encode(prompt_text, return_tensors="pt")
output = model.generate(
input_ids=input_ids,
max_length=max_length,
num_return_sequences=num_return_sequences,
temperature=temperature,
pad_token_id=tokenizer.eos_token_id
)
return [tokenizer.decode(ids, skip_special_tokens=True) for ids in output]
Step 4: GPT-2 Prompt Generation Demo
Uses prompt generation function with input text "Once upon a time", generates and prints resulting prompts. This showcases the practical application of the function for generating text prompts using GPT-2.
# Example usageprompt_text = "Once upon a time"
print("Generated Prompt:")
for prompt in generated_prompts:
print(prompt)
generated_prompts = generate_prompt(prompt_text)
Generated Output Prompt:
Once upon a time, there was a man who lived in a cave, and he was a good man. He was a good man because he was a good man. He was a good man because he was a good man.
Now, Implementation of Prompt Generation Using GPT-Neo
Step 1: Utilizing GPT-Neo for Text Generation via Hugging Face Pipeline
The code utilizes Hugging Face's pipeline for text generation, simplifying access to a GPT-Neo model for prompt generation tasks.
# Use a pipeline as a high-level helperfrom transformers import pipeline
pipe = pipeline("text-generation", model="usamakenway/Stable-diffusion-prompt-generator-gpt-neo")
Step 2: Load model
The code directly loads a GPT-Neo model and tokenizer from Hugging Face's Transformers library. It allows immediate access to the model for text generation tasks, such as completion and dialogue systems.
# Load model directlyfrom transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("usamakenway/Stable-diffusion-prompt-generator-gpt-neo")
model = AutoModelForCausalLM.from_pretrained("usamakenway/Stable-diffusion-prompt-generator-gpt-neo")
Step 3: GPT-Neo Prompt Generation Function
The code Defines a prompt generation function using GPT-2 model, encoding input, generating prompt continuations, and decoding output for readability.
# Define prompt generation functiondef generate_prompt(prompt_text, max_length=50, num_return_sequences=1, temperature=1.0):
input_ids = tokenizer.encode(prompt_text, return_tensors="pt")
output = model.generate(
input_ids=input_ids,
max_length=max_length,
num_return_sequences=num_return_sequences,
temperature=temperature,
pad_token_id=tokenizer.eos_token_id
)
return [tokenizer.decode(ids, skip_special_tokens=True) for ids in output]
Step 4: GPT-Neo Prompt Generation Demo
Uses prompt generation function with input text "Once upon a time", generates and prints resulting prompts.
# Example usageprompt_text = "Once upon a time"
print("Generated Prompt:")
for prompt in generated_prompts:
print(prompt)
generated_prompts = generate_prompt(prompt_text)
Generated Output Prompt:
Once upon a time machine, intricate, elegant, highly detailed, digital painting, artstation, concept art, smooth, sharp focus, illustration, art by artgerm and greg rutkowski and alphonse mucha"
Implementation of Generation Prompt Using GPT-4
Let’s go through a simple code to understand things better:
Step 1: Installation of OpenAI Library
!pip install openaiStep 2: Importing Necessary Libraries
OpenAI's API, driven by models like GPT-3, GPT-4 allows developers to generate human-like Prompt with ease. This advanced technology finds applications in chatbots, content creation, translation, and more, making it accessible for diverse software integrations.
import osimport openai
Step 3: Setting Up OpenAI API Key
# Replace with your OpenAI API keyopenai.api_key = os.environ.get("OPENAI_API_KEY")
Step 4: Initializing OpenAI Client
from openai import OpenAIclient = OpenAI(api_key='Typing Your OPENAI_API_KEY')
Step 5: Defining Function to Generate API Validation Tests
This Python function `generate_api_validation` sends a request to an AI model API, likely OpenAI's GPT-4, to generate text based on a given prompt. It specifies parameters like model type, prompt, maximum tokens, and temperature for text generation, then returns the generated text response.
def generate_api_validation(Prompt_Generated, max_tokens=20, temperature=0.7):response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You help create a full prompt"},
{"role": "user", "content": Prompt_Generated}
],
max_tokens=max_tokens,
temperature=temperature
)
return response.choices[0].message.content
Step 6: This code initializes a prompt "Once upon a time" and generates API validation tests using a function called `generate_api_validation`. It specifies parameters like maximum tokens and temperature for text generation. The generated tests are then printed. It's likely part of a testing or validation framework for an AI text generation API.
Prompt_Text = "Once upon a time"api_validation_tests = generate_api_validation(Prompt_Text, max_tokens=20, temperature=0.5)
print("Generated Prompt:")
print(api_validation_tests)
Generated Output Prompt
Once upon a time,in a land filled with magic and mystery, there lived a young and curious fairy named Aurelia.Conclusion
Harnessing GPT-2, GPT-Neo and GPT-4 for prompt generation streamlines text creation, enabling coherent and contextually relevant output. Accessible via pipelines or direct loading, these models automate text generation tasks, revolutionizing content creation and dialogue systems.