- Getting Started with Generative Artificial Intelligence
- Mastering Image Generation Techniques with Generative Models
- Generating Art with Neural Style Transfer
- Exploring Deep Dream and Neural Style Transfer
- A Guide to 3D Object Generation with Generative Models
- Text Generation with Generative Models
- Language Generation Models for Prompt Generation
- Chatbots with Generative AI Models
- Music Generation with Generative Models
- A Beginner’s Guide to Generative Design
- Video Generation with Generative Models
- Anime Generation with Generative Models
- Generative Adversarial Networks (GANs)
- Generative modeling using Variational AutoEncoders
- Reinforcement Learning for Generation
- Interactive Generative Systems
- Fashion Generation with Generative Models
- Story Generation with Generative Models
- Character Generation with Generative AI
- Generative Modeling for Simulation
- Data Augmentation Techniques with Generative Models
- Future Directions in Generative AI
Data Augmentation Techniques with Generative Models | Generative AI

Introduction
Augmenting data is essential for training machine learning models, particularly when working with small datasets. Although generative modelling has arisen and is producing synthetic data such as GANs and VAEs, traditional approaches such as translation and rotation are still used. This increases the diversity of input and strengthens machine learning models' capacity for generalization.
Importance of Data Augmentation Techniques with Generative Models
Enhanced Diversity: While generative models enhance robustness and generalizability in training models by learning complicated patterns and generating different samples, traditional augmentation strategies could not adequately capture data variability.
- Addressing Data Imbalance: By creating synthetic samples, generating synthetic data, and minimizing the consequences of fewer samples in particular classes, generative models can address data imbalance caused by oversampling minority groups.
- Privacy Preservation: Because generative models learn the distribution of data without directly exposing sensitive information, they provide a solution to privacy problems in applications such as financial data analysis and medical imaging. This is because synthetic data may be used for training.
- Data Augmentation on Small Datasets: In domains with limited datasets, generative models can improve the performance of deep learning models by generating more samples and enlarging the training set.
- Transfer Learning: High-quality synthetic samples can be produced by pre-trained models on a variety of datasets, which improve transfer learning performance by adding domain-specific features to training data.
Let’s dive into these data augmentation techniques with generative models
- GAN
Overview data augmentation techniques using GAN
Using Generative Adversarial Networks (GANs) to create synthetic data samples enhances model generalization and tackles issues such as data imbalance and privacy protection in data augmentation techniques.
The Workflow:
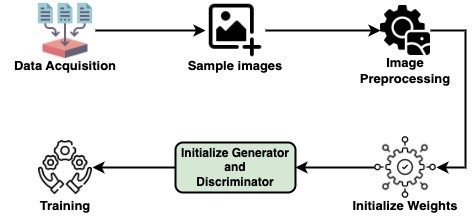
Implementation of data augmentation techniques using GAN
Let’s go through a simple code to understand things better:
Step 1: Importing
import os
print(os.listdir("../input/diabetic-retinopathy-dataset/"))
from __future__ import print_function
import time
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
from torch.autograd import Variable
import matplotlib.pyplot as plt
import numpy as np
from torch import nn, optim
import torch.nn.functional as F
from torchvision import datasets, transforms
from torchvision.utils import save_image
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
from tqdm import tqdm_notebook as tqdm
import time
import random
import glob
import cv2
from PIL import Image
Step 2: Sample Images
Healthy
PATH1 = '../input/diabetic-retinopathy-dataset/Healthy/'
images = os.listdir(PATH1)
print(f'There are {len(os.listdir(PATH1))} pictures of Healthy.')
fig, axes = plt.subplots(nrows=3, ncols=3, figsize=(12,10))
for indx, axis in enumerate(axes.flatten()):
rnd_indx = np.random.randint(0, len(os.listdir(PATH1)))
img = plt.imread(PATH1 + images[rnd_indx])
imgplot = axis.imshow(img)
axis.set_title(images[rnd_indx])
axis.set_axis_off()
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
Output
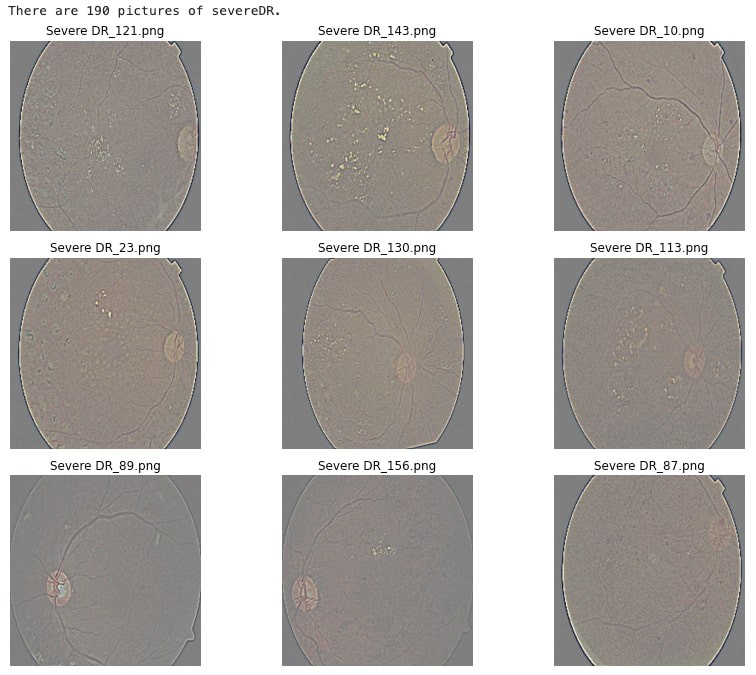
Severe
PATH2 = '../input/diabetic-retinopathy-dataset/Severe DR/'
images2 = os.listdir(PATH2)
print(f'There are {len(os.listdir(PATH2))} pictures of severeDR.')
fig, axes = plt.subplots(nrows=3, ncols=3, figsize=(12,10))
for indx, axis in enumerate(axes.flatten()):
rnd_indx = np.random.randint(0, len(os.listdir(PATH2)))
img = plt.imread(PATH2 + images2[rnd_indx])
imgplot = axis.imshow(img)
axis.set_title(images2[rnd_indx])
axis.set_axis_off()
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
Output

Step 3: Image Preprocessing
batch_size = 32
batchSize = 64
imageSize = 64
# 64x64 images!
transform = transforms.Compose([transforms.Resize(64),
transforms.CenterCrop(64),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_data = datasets.ImageFolder('../input/diabetic-retinopathy-dataset/', transform=transform)
dataloader = torch.utils.data.DataLoader(train_data, shuffle=True,
batch_size=batch_size)
imgs, label = next(iter(dataloader))
imgs = imgs.numpy().transpose(0, 2, 3, 1)
batch_size = 32
image_size = 64
random_transforms = [transforms.ColorJitter(), transforms.RandomRotation(degrees=20)]
transform = transforms.Compose([transforms.Resize(64),
transforms.CenterCrop(64),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply(random_transforms, p=0.2),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_data = datasets.ImageFolder('../input/diabetic-retinopathy-dataset/', transform=transform)
train_loader = torch.utils.data.DataLoader(train_data, shuffle=True,
batch_size=batch_size)
imgs, label = next(iter(train_loader))
imgs = imgs.numpy().transpose(0, 2, 3, 1)
train_dataOutput:
Dataset ImageFolderNumber of datapoints: 2750
Root location: ../input/diabetic-retinopathy-dataset/
StandardTransform
Transform: Compose(
Resize(size=64, interpolation=bilinear, max_size=None, antialias=None)
CenterCrop(size=(64, 64))
RandomHorizontalFlip(p=0.5)
RandomApply(
p=0.2
ColorJitter(brightness=None, contrast=None, saturation=None, hue=None)
RandomRotation(degrees=[-20.0, 20.0], interpolation=nearest, expand=False, fill=0)
)
ToTensor()
Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
)
for i in range(5):
plt.imshow(imgs[i])
plt.show()
Output:
Step 4: Weights
defweights_init(m):
"""
Takes as input a neural network m that will initialize all its weights.
"""
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
Step 5: Generator
classG(nn.Module):
def__init__(self):
super(G, self).__init__()
self.main = nn.Sequential(
nn.ConvTranspose2d(100, 512, 4, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.ConvTranspose2d(512, 256, 4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.ConvTranspose2d(256, 128, 4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.ConvTranspose2d(64, 3, 4, stride=2, padding=1, bias=False),
nn.Tanh()
)
defforward(self, input):
output = self.main(input)
return output
netG = G()
netG.apply(weights_init)
output
G(
(main): Sequential(
(0): ConvTranspose2d(100, 512, kernel_size=(4, 4), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(7): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(13): Tanh()
)
)
Step 6: Discriminator
classD(nn.Module):
def__init__(self):
super(D, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(3, 64, 4, stride=2, padding=1, bias=False),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
nn.Conv2d(64, 128, 4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
nn.Conv2d(128, 256, 4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
nn.Conv2d(256, 512, 4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(512),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
nn.Conv2d(512, 1, 4, stride=1, padding=0, bias=False),
nn.Sigmoid()
)
defforward(self, input):
output = self.main(input)
return output.view(-1)
netD = D()
netD.apply(weights_init)
output
D(
(main): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): LeakyReLU(negative_slope=0.2, inplace=True)
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): LeakyReLU(negative_slope=0.2, inplace=True)
(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)
(12): Sigmoid()
)
)
classGenerator(nn.Module):
def__init__(self, nz=128, channels=3):
super(Generator, self).__init__()
self.nz = nz
self.channels = channels
defconvlayer(n_input, n_output, k_size=4, stride=2, padding=0):
block = [
nn.ConvTranspose2d(n_input, n_output, kernel_size=k_size, stride=stride, padding=padding, bias=False),
nn.BatchNorm2d(n_output),
nn.ReLU(inplace=True),
]
return block
self.model = nn.Sequential(
*convlayer(self.nz, 1024, 4, 1, 0), # Fully connected layer via convolution.
*convlayer(1024, 512, 4, 2, 1),
*convlayer(512, 256, 4, 2, 1),
*convlayer(256, 128, 4, 2, 1),
*convlayer(128, 64, 4, 2, 1),
nn.ConvTranspose2d(64, self.channels, 3, 1, 1),
nn.Tanh()
)
defforward(self, z):
z = z.view(-1, self.nz, 1, 1)
img = self.model(z)
return img
classDiscriminator(nn.Module):
def__init__(self, channels=3):
super(Discriminator, self).__init__()
self.channels = channels
defconvlayer(n_input, n_output, k_size=4, stride=2, padding=0, bn=False):
block = [nn.Conv2d(n_input, n_output, kernel_size=k_size, stride=stride, padding=padding, bias=False)]
if bn:
block.append(nn.BatchNorm2d(n_output))
block.append(nn.LeakyReLU(0.2, inplace=True))
return block
self.model = nn.Sequential(
*convlayer(self.channels, 32, 4, 2, 1),
*convlayer(32, 64, 4, 2, 1),
*convlayer(64, 128, 4, 2, 1, bn=True),
*convlayer(128, 256, 4, 2, 1, bn=True),
nn.Conv2d(256, 1, 4, 1, 0, bias=False), # FC with Conv.
)
defforward(self, imgs):
logits = self.model(imgs)
out = torch.sigmoid(logits)
return out.view(-1, 1)
Step 7: Training
!mkdir results!ls
EPOCH = 1
LR = 0.0001
criterion = nn.BCELoss()
optimizerD = optim.Adam(netD.parameters(), lr=LR, betas=(0.5, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=LR, betas=(0.5, 0.999))
for epoch in range(EPOCH):
for i, data in enumerate(dataloader, 0):
netD.zero_grad()
real,_ = data
input = Variable(real)
target = Variable(torch.ones(input.size()[0]))
output = netD(input)
errD_real = criterion(output, target)
noise = Variable(torch.randn(input.size()[0], 100, 1, 1))
fake = netG(noise)
target = Variable(torch.zeros(input.size()[0]))
output = netD(fake.detach())
errD_fake = criterion(output, target)
errD = errD_real + errD_fake
errD.backward()
optimizerD.step()
netG.zero_grad()
target = Variable(torch.ones(input.size()[0]))
output = netD(fake)
errG = criterion(output, target)
errG.backward()
optimizerG.step()
print('[%d/%d][%d/%d] Loss_D: %.4f; Loss_G: %.4f' % (epoch, EPOCH, i, len(dataloader), errD.item(), errG.item()))
if i % 100 == 0:
vutils.save_image(real, '%s/real_samples.png' % "./results", normalize=True)
fake = netG(noise)
vutils.save_image(fake.data, '%s/fake_samples_epoch_%03d.png' % ("./results", epoch), normalize=True)
output
[0/1][0/86] Loss_D: 2.0882; Loss_G: 2.4661
[0/1][1/86] Loss_D: 1.1516; Loss_G: 2.9674
[0/1][2/86] Loss_D: 0.6896; Loss_G: 3.6825
[0/1][3/86] Loss_D: 0.4992; Loss_G: 4.2080
[0/1][4/86] Loss_D: 0.1983; Loss_G: 4.3615
[0/1][5/86] Loss_D: 0.1868; Loss_G: 4.4660
[0/1][6/86] Loss_D: 0.2880; Loss_G: 4.0734
………………………………………………………………
………………………………………………………………
[0/1][79/86] Loss_D: 0.1594; Loss_G: 12.1990
[0/1][80/86] Loss_D: 0.0810; Loss_G: 12.0702
[0/1][81/86] Loss_D: 0.0114; Loss_G: 9.4993
[0/1][82/86] Loss_D: 0.0739; Loss_G: 6.0370
[0/1][83/86] Loss_D: 0.3512; Loss_G: 15.6625
[0/1][84/86] Loss_D: 0.0967; Loss_G: 17.0006
[0/1][85/86] Loss_D: 0.1868; Loss_G: 14.9242
batch_size = 32
LR_G = 0.0005
LR_D = 0.0001
beta1 = 0.5
epochs = 100
real_label = 0.9
fake_label = 0
nz = 128
device = torch.device("cuda"if torch.cuda.is_available() else"cpu")
netG = Generator(nz).to(device)
netD = Discriminator().to(device)
criterion = nn.BCELoss()
optimizerD = optim.Adam(netD.parameters(), lr=LR_D, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=LR_G, betas=(beta1, 0.999))
fixed_noise = torch.randn(25, nz, 1, 1, device=device)
G_losses = []
D_losses = []
epoch_time = []
defplot_loss(G_losses, D_losses, epoch):
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss - EPOCH "+ str(epoch))
plt.plot(G_losses,label="G")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
defshow_generated_img(n_images=5):
sample = []
for _ in range(n_images):
noise = torch.randn(1, nz, 1, 1, device=device)
gen_image = netG(noise).to("cpu").clone().detach().squeeze(0)
gen_image = gen_image.numpy().transpose(1, 2, 0)
sample.append(gen_image)
figure, axes = plt.subplots(1, len(sample), figsize = (64,64))
for index, axis in enumerate(axes):
axis.axis('off')
image_array = sample[index]
axis.imshow(image_array)
plt.show()
plt.close()
for epoch in range(epochs):
start = time.time()
for ii, (real_images, train_labels) in tqdm(enumerate(train_loader), total=len(train_loader)):
netD.zero_grad()
real_images = real_images.to(device)
batch_size = real_images.size(0)
labels = torch.full((batch_size, 1), real_label, device=device)
output = netD(real_images)
errD_real = criterion(output, labels)
errD_real.backward()
D_x = output.mean().item()
noise = torch.randn(batch_size, nz, 1, 1, device=device)
fake = netG(noise)
labels.fill_(fake_label)
output = netD(fake.detach())
errD_fake = criterion(output, labels)
errD_fake.backward()
D_G_z1 = output.mean().item()
errD = errD_real + errD_fake
optimizerD.step()
netG.zero_grad()
labels.fill_(real_label) # fake labels are real for generator cost
output = netD(fake)
errG = criterion(output, labels)
errG.backward()
D_G_z2 = output.mean().item()
optimizerG.step()
G_losses.append(errG.item())
D_losses.append(errD.item())
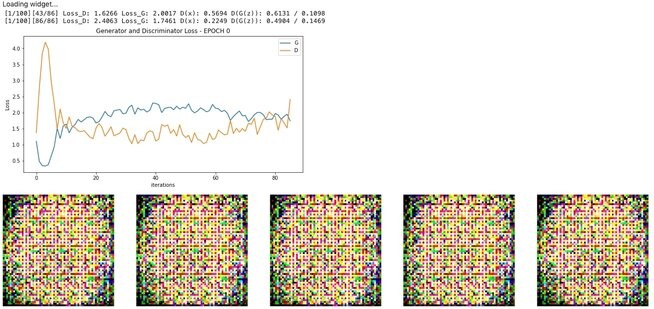
if (ii+1) % (len(train_loader)//2) == 0:
print('[%d/%d][%d/%d] Loss_D: %.4f Loss_G: %.4f D(x): %.4f D(G(z)): %.4f / %.4f'
% (epoch + 1, epochs, ii+1, len(train_loader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
plot_loss (G_losses, D_losses, epoch)
G_losses = []
D_losses = []
if epoch % 10 == 0:
show_generated_img()
epoch_time.append(time.time()- start)
#valid_image = netG(fixed_noise)
output
—--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Conclusion
In order to enhance the training of machine learning models, the study investigates data augmentation methods utilizing Generative Adversarial Networks (GANs). Training diversity is increased by GANs' generation of synthetic data samples. Preprocessing images, creating and refining models, and using training samples are all part of implementation.