- Getting Started with Generative Artificial Intelligence
- Mastering Image Generation Techniques with Generative Models
- Generating Art with Neural Style Transfer
- Exploring Deep Dream and Neural Style Transfer
- A Guide to 3D Object Generation with Generative Models
- Text Generation with Generative Models
- Language Generation Models for Prompt Generation
- Chatbots with Generative AI Models
- Music Generation with Generative Models
- A Beginner’s Guide to Generative Design
- Video Generation with Generative Models
- Anime Generation with Generative Models
- Generative Adversarial Networks (GANs)
- Generative modeling using Variational AutoEncoders
- Reinforcement Learning for Generation
- Interactive Generative Systems
- Fashion Generation with Generative Models
- Story Generation with Generative Models
- Character Generation with Generative AI
- Generative Modeling for Simulation
- Data Augmentation Techniques with Generative Models
- Future Directions in Generative AI
Fashion Generation with Generative Models | Generative AI

Introduction
Generative models in fashion creation provide a novel convergence of artificial intelligence and the dynamic fashion industry. By utilizing sophisticated algorithms, these models have the ability to independently generate novel patterns, styles, and trends, expanding the frontiers of creativity and revolutionizing the fashion industry. The use of generative models in the fashion industry creates a world of opportunities for designers, businesses, and customers alike, from creating one-of-a-kind clothing to forecasting next trends.
Importance of Fashion Generation
Generative models are essential for fashion generation in numerous important aspects for the industry:
Unleashing Creativity: This approach frees designers to experiment with new concepts and push artistic boundaries, producing visually striking designs.
Efficiency in Design Process: This results in more refined designs by streamlining activities, saving time, and enabling designers to concentrate on conception.
Customization and Personalization: Provides customers with specialized designs that enhance their unique shopping experience and sense of style.
Sustainability and Waste Reduction: Promotes eco-friendly behaviors, reduces overstock, and makes on-demand production easier.
Forecasting Trends: This method helps companies remain competitive and relevant in the market by properly predicting trends through data analysis.
Encouraging Collaboration and Innovation: Promotes cross-disciplinary cooperation, which propels the creation of novel concepts and technology.
Some of the Fashion Generation models are
- Autoencoder (AE)
- Generative Adversarial Network (GAN)
- Wasserstein GAN with Gradient Penalty (WGAN-GP)
- VAE-GAN
Let’s dive into these models :
Autoencoder (AE)
An autoencoder (AE) is a type of neural network that learns to compress and reconstruct data, useful for tasks like data denoising and dimensionality reduction.
A simple autoencoder network.
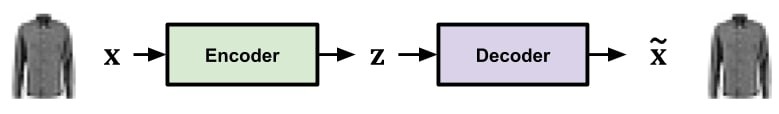
Implementation of Fashion Generation Using Autoencoder (AE)
Step 1: Install packages if in colab
### install necessary packages if in colab
defrun_subprocess_command(cmd):
process = subprocess.Popen(cmd.split(), stdout=subprocess.PIPE)
for line in process.stdout:
print(line.decode().strip())
import sys, subprocess
IN_COLAB = "google.colab"in sys.modules
colab_requirements = ["pip install tf-nightly-gpu-2.0-preview==2.0.0.dev20190513"]
if IN_COLAB:
for i in colab_requirements:
run_subprocess_command(i)
Step 2: load packages
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tqdm.autonotebook import tqdm
%matplotlib inline
from IPython import display
import pandas as pd
Step 3: Create a fashion-MNIST dataset
TRAIN_BUF=60000
BATCH_SIZE=512
TEST_BUF=10000
DIMS = (28,28,1)
N_TRAIN_BATCHES =int(TRAIN_BUF/BATCH_SIZE)
N_TEST_BATCHES = int(TEST_BUF/BATCH_SIZE)
# load dataset
(train_images, _), (test_images, _) = tf.keras.datasets.fashion_mnist.load_data()
# split dataset
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype(
"float32"
) / 255.0
test_images = test_images.reshape(test_images.shape[0], 28, 28, 1).astype("float32") / 255.0
# batch datasets
train_dataset = (
tf.data.Dataset.from_tensor_slices(train_images)
.shuffle(TRAIN_BUF)
.batch(BATCH_SIZE)
)
test_dataset = (
tf.data.Dataset.from_tensor_slices(test_images)
.shuffle(TEST_BUF)
.batch(BATCH_SIZE)
)
Output
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
29515/29515 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26421880/26421880 [==============================] - 1s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
5148/5148 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4422102/4422102 [==============================] - 1s 0us/step
Step 4: Define the network as tf.keras.model object
classAE(tf.keras.Model):
"""a basic autoencoder class for tensorflow
Extends:
tf.keras.Model
"""
def__init__(self, **kwargs):
super(AE, self).__init__()
self.__dict__.update(kwargs)
self.enc = tf.keras.Sequential(self.enc)
self.dec = tf.keras.Sequential(self.dec)
@tf.function
defencode(self, x):
return self.enc(x)
@tf.function
defdecode(self, z):
return self.dec(z)
@tf.function
defcompute_loss(self, x):
z = self.encode(x)
_x = self.decode(z)
ae_loss = tf.reduce_mean(tf.square(x - _x))
return ae_loss
@tf.function
defcompute_gradients(self, x):
with tf.GradientTape() as tape:
loss = self.compute_loss(x)
return tape.gradient(loss, self.trainable_variables)
deftrain(self, train_x):
gradients = self.compute_gradients(train_x)
self.optimizer.apply_gradients(zip(gradients, self.trainable_variables))
Step 5: Define the network architecture
Step 6: Create Model
optimizer = tf.keras.optimizers.Adam(1e-3)
model = AE(
enc = encoder,
dec = decoder,
optimizer = optimizer,
)
Step 7: Train the model
example_data = next(iter(train_dataset))
defplot_reconstruction(model, example_data, nex=5, zm=3):
example_data_reconstructed = model.decode(model.encode(example_data))
fig, axs = plt.subplots(ncols=nex, nrows=2, figsize=(zm * nex, zm * 2))
for exi in range(nex):
axs[0, exi].matshow(
example_data.numpy()[exi].squeeze(), cmap=plt.cm.Greys, vmin=0, vmax=1
)
axs[1, exi].matshow(
example_data_reconstructed.numpy()[exi].squeeze(),
cmap=plt.cm.Greys,
vmin=0,
vmax=1,
)
for ax in axs.flatten():
ax.axis("off")
plt.show()
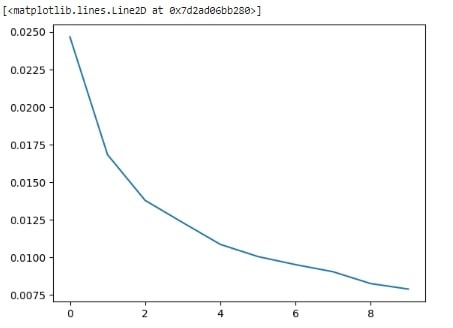
losses = pd.DataFrame(columns = ['MSE'])n_epochs = 10
for epoch in range(n_epochs):
# train
for batch, train_x in tqdm(
zip(range(N_TRAIN_BATCHES), train_dataset), total=N_TRAIN_BATCHES
):
model.train(train_x)
# test on holdout
loss = []
for batch, test_x in tqdm(
zip(range(N_TRAIN_BATCHES), train_dataset), total=N_TRAIN_BATCHES
):
loss.append(model.compute_loss(train_x))
losses.loc[len(losses)] = np.mean(loss, axis=0)
# plot results
display.clear_output()
print("Epoch: {} | MSE: {}".format(epoch, losses.MSE.values[-1]))
plot_reconstruction(model, example_data)
Output

plt.plot(losses.MSE.values)Output
Generative Adversarial Network (GAN)
A Generative Adversarial Network (GAN) is a neural network with two subnetworks, encoder and decoder, trained on opposing loss functions. The encoder produces indistinguishable data, while the decoder distinguishes between produced and actual data.
A simple autoencoder network.

Implementation of Fashion Generation Using Generative Adversarial Network (GAN)
Step 1: Install packages if in colab
defrun_subprocess_command(cmd):
process = subprocess.Popen(cmd.split(), stdout=subprocess.PIPE)
for line in process.stdout:
print(line.decode().strip())
import sys, subprocess
IN_COLAB = "google.colab"in sys.modules
colab_requirements = ["pip install tf-nightly-gpu-2.0-preview==2.0.0.dev20190513"]
if IN_COLAB:
for i in colab_requirements:
run_subprocess_command(i)
Step 2: load packages
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tqdm.autonotebook import tqdm
%matplotlib inline
from IPython import display
import pandas as pd
Step 3: Create a fashion-MNIST dataset
TRAIN_BUF=60000
BATCH_SIZE=512
TEST_BUF=10000
DIMS = (28,28,1)
N_TRAIN_BATCHES =int(TRAIN_BUF/BATCH_SIZE)
N_TEST_BATCHES = int(TEST_BUF/BATCH_SIZE)
# load dataset
(train_images, _), (test_images, _) = tf.keras.datasets.fashion_mnist.load_data()
# split dataset
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype(
"float32"
) / 255.0
test_images = test_images.reshape(test_images.shape[0], 28, 28, 1).astype("float32") / 255.0
# batch datasets
train_dataset = (
tf.data.Dataset.from_tensor_slices(train_images)
.shuffle(TRAIN_BUF)
.batch(BATCH_SIZE)
)
test_dataset = (
tf.data.Dataset.from_tensor_slices(test_images)
.shuffle(TEST_BUF)
.batch(BATCH_SIZE)
)
Step 4: Define the network as tf.keras.model object
classGAN(tf.keras.Model):
""" a basic GAN class
Extends:
tf.keras.Model
"""
def__init__(self, **kwargs):
super(GAN, self).__init__()
self.__dict__.update(kwargs)
self.gen = tf.keras.Sequential(self.gen)
self.disc = tf.keras.Sequential(self.disc)
defgenerate(self, z):
return self.gen(z)
defdiscriminate(self, x):
return self.disc(x)
defcompute_loss(self, x):
""" passes through the network and computes loss
"""
# generating noise from a uniform distribution
z_samp = tf.random.normal([x.shape[0], 1, 1, self.n_Z])
# run noise through generator
x_gen = self.generate(z_samp)
# discriminate x and x_gen
logits_x = self.discriminate(x)
logits_x_gen = self.discriminate(x_gen)
### losses
# losses of real with label "1"
disc_real_loss = gan_loss(logits=logits_x, is_real=True)
# losses of fake with label "0"
disc_fake_loss = gan_loss(logits=logits_x_gen, is_real=False)
disc_loss = disc_fake_loss + disc_real_loss
# losses of fake with label "1"
gen_loss = gan_loss(logits=logits_x_gen, is_real=True)
return disc_loss, gen_loss
defcompute_gradients(self, x):
""" passes through the network and computes loss
"""
### pass through network
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
disc_loss, gen_loss = self.compute_loss(x)
# compute gradients
gen_gradients = gen_tape.gradient(gen_loss, self.gen.trainable_variables)
disc_gradients = disc_tape.gradient(disc_loss, self.disc.trainable_variables)
return gen_gradients, disc_gradients
defapply_gradients(self, gen_gradients, disc_gradients):
self.gen_optimizer.apply_gradients(
zip(gen_gradients, self.gen.trainable_variables)
)
self.disc_optimizer.apply_gradients(
zip(disc_gradients, self.disc.trainable_variables)
)
@tf.function
deftrain(self, train_x):
gen_gradients, disc_gradients = self.compute_gradients(train_x)
self.apply_gradients(gen_gradients, disc_gradients)
defgan_loss(logits, is_real=True):
"""Computes standard gan loss between logits and labels
"""
if is_real:
labels = tf.ones_like(logits)
else:
labels = tf.zeros_like(logits)
return tf.compat.v1.losses.sigmoid_cross_entropy(
multi_class_labels=labels, logits=logits
)
Step 5: Define the network architecture
N_Z = 64
generator = [
tf.keras.layers.Dense(units=7 * 7 * 64, activation="relu"),
tf.keras.layers.Reshape(target_shape=(7, 7, 64)),
tf.keras.layers.Conv2DTranspose(
filters=64, kernel_size=3, strides=(2, 2), padding="SAME", activation="relu"
),
tf.keras.layers.Conv2DTranspose(
filters=32, kernel_size=3, strides=(2, 2), padding="SAME", activation="relu"
),
tf.keras.layers.Conv2DTranspose(
filters=1, kernel_size=3, strides=(1, 1), padding="SAME", activation="sigmoid"
),
]
discriminator = [
tf.keras.layers.InputLayer(input_shape=DIMS),
tf.keras.layers.Conv2D(
filters=32, kernel_size=3, strides=(2, 2), activation="relu"
),
tf.keras.layers.Conv2D(
filters=64, kernel_size=3, strides=(2, 2), activation="relu"
),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=1, activation=None),
]
Step 6: Create Model
gen_optimizer = tf.keras.optimizers.Adam(0.001, beta_1=0.5)
disc_optimizer = tf.keras.optimizers.RMSprop(0.005)
model = GAN(
gen = generator,
disc = discriminator,
gen_optimizer = gen_optimizer,
disc_optimizer = disc_optimizer,
n_Z = N_Z
)
Step 7: Train the model
# exampled data for plotting results
defplot_reconstruction(model, nex=8, zm=2):
samples = model.generate(tf.random.normal(shape=(BATCH_SIZE, N_Z)))
fig, axs = plt.subplots(ncols=nex, nrows=1, figsize=(zm * nex, zm))
for axi in range(nex):
axs[axi].matshow(
samples.numpy()[axi].squeeze(), cmap=plt.cm.Greys, vmin=0, vmax=1
)
axs[axi].axis('off')
plt.show()
losses = pd.DataFrame(columns = ['disc_loss', 'gen_loss'])
n_epochs = 50
for epoch in range(n_epochs):
# train
for batch, train_x in tqdm(
zip(range(N_TRAIN_BATCHES), train_dataset), total=N_TRAIN_BATCHES
):
model.train(train_x)
# test on holdout
loss = []
for batch, test_x in tqdm(
zip(range(N_TEST_BATCHES), test_dataset), total=N_TEST_BATCHES
):
loss.append(model.compute_loss(train_x))
losses.loc[len(losses)] = np.mean(loss, axis=0)
# plot results
display.clear_output()
print(
"Epoch: {} | disc_loss: {} | gen_loss: {}".format(
epoch, losses.disc_loss.values[-1], losses.gen_loss.values[-1]
)
)
plot_reconstruction(model)
Output
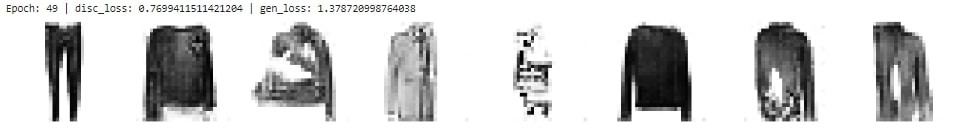
Wasserstein GAN with Gradient Penalty (WGAN-GP)
Wasserstein GAN with Gradient Penalty (WGAN-GP) is an advanced variant of GANs that improves stability and training quality by using the Wasserstein distance metric and adding a gradient penalty term.
A GAN that enhances training stability over the original loss function is called WGAN-GP.

Step 1: Install packages if in colab
defrun_subprocess_command(cmd):
process = subprocess.Popen(cmd.split(), stdout=subprocess.PIPE)
for line in process.stdout:
print(line.decode().strip())
import sys, subprocess
IN_COLAB = 'google.colab'in sys.modules
colab_requirements = ['pip install tf-nightly-gpu-2.0-preview==2.0.0.dev20190513']
if IN_COLAB:
for i in colab_requirements:
run_subprocess_command(i)
Step 2: load packages
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tqdm.autonotebook import tqdm
%matplotlib inline
from IPython import display
import pandas as pd
Step 3: Create a fashion-MNIST dataset
TRAIN_BUF=60000
BATCH_SIZE=512
TEST_BUF=10000
DIMS = (28,28,1)
N_TRAIN_BATCHES =int(TRAIN_BUF/BATCH_SIZE)
N_TEST_BATCHES = int(TEST_BUF/BATCH_SIZE)
# load dataset
(train_images, _), (test_images, _) = tf.keras.datasets.fashion_mnist.load_data()
# split dataset
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype(
"float32"
) / 255.0
test_images = test_images.reshape(test_images.shape[0], 28, 28, 1).astype("float32") / 255.0
# batch datasets
train_dataset = (
tf.data.Dataset.from_tensor_slices(train_images)
.shuffle(TRAIN_BUF)
.batch(BATCH_SIZE)
)
test_dataset = (
tf.data.Dataset.from_tensor_slices(test_images)
.shuffle(TEST_BUF)
.batch(BATCH_SIZE)
)
Step 4: Define the network as tf.keras.model object
classWGAN(tf.keras.Model):
"""[summary]
I used github/LynnHo/DCGAN-LSGAN-WGAN-GP-DRAGAN-Tensorflow-2/ as a reference on this.
Extends:
tf.keras.Model
"""
def__init__(self, **kwargs):
super(WGAN, self).__init__()
self.__dict__.update(kwargs)
self.gen = tf.keras.Sequential(self.gen)
self.disc = tf.keras.Sequential(self.disc)
defgenerate(self, z):
return self.gen(z)
defdiscriminate(self, x):
return self.disc(x)
defcompute_loss(self, x):
""" passes through the network and computes loss
"""
### pass through network
# generating noise from a uniform distribution
z_samp = tf.random.normal([x.shape[0], 1, 1, self.n_Z])
# run noise through generator
x_gen = self.generate(z_samp)
# discriminate x and x_gen
logits_x = self.discriminate(x)
logits_x_gen = self.discriminate(x_gen)
# gradient penalty
d_regularizer = self.gradient_penalty(x, x_gen)
### losses
disc_loss = (
tf.reduce_mean(logits_x)
- tf.reduce_mean(logits_x_gen)
+ d_regularizer * self.gradient_penalty_weight
)
# losses of fake with label "1"
gen_loss = tf.reduce_mean(logits_x_gen)
return disc_loss, gen_loss
defcompute_gradients(self, x):
""" passes through the network and computes loss
"""
### pass through network
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
disc_loss, gen_loss = self.compute_loss(x)
# compute gradients
gen_gradients = gen_tape.gradient(gen_loss, self.gen.trainable_variables)
disc_gradients = disc_tape.gradient(disc_loss, self.disc.trainable_variables)
return gen_gradients, disc_gradients
defapply_gradients(self, gen_gradients, disc_gradients):
self.gen_optimizer.apply_gradients(
zip(gen_gradients, self.gen.trainable_variables)
)
self.disc_optimizer.apply_gradients(
zip(disc_gradients, self.disc.trainable_variables)
)
defgradient_penalty(self, x, x_gen):
epsilon = tf.random.uniform([x.shape[0], 1, 1, 1], 0.0, 1.0)
x_hat = epsilon * x + (1 - epsilon) * x_gen
with tf.GradientTape() as t:
t.watch(x_hat)
d_hat = self.discriminate(x_hat)
gradients = t.gradient(d_hat, x_hat)
ddx = tf.sqrt(tf.reduce_sum(gradients ** 2, axis=[1, 2]))
d_regularizer = tf.reduce_mean((ddx - 1.0) ** 2)
return d_regularizer
@tf.function
deftrain(self, train_x):
gen_gradients, disc_gradients = self.compute_gradients(train_x)
self.apply_gradients(gen_gradients, disc_gradients)
Step 5: Define the network architecture
N_Z = 64
generator = [
tf.keras.layers.Dense(units=7 * 7 * 64, activation="relu"),
tf.keras.layers.Reshape(target_shape=(7, 7, 64)),
tf.keras.layers.Conv2DTranspose(
filters=64, kernel_size=3, strides=(2, 2), padding="SAME", activation="relu"
),
tf.keras.layers.Conv2DTranspose(
filters=32, kernel_size=3, strides=(2, 2), padding="SAME", activation="relu"
),
tf.keras.layers.Conv2DTranspose(
filters=1, kernel_size=3, strides=(1, 1), padding="SAME", activation="sigmoid"
),
]
discriminator = [
tf.keras.layers.InputLayer(input_shape=DIMS),
tf.keras.layers.Conv2D(
filters=32, kernel_size=3, strides=(2, 2), activation="relu"
),
tf.keras.layers.Conv2D(
filters=64, kernel_size=3, strides=(2, 2), activation="relu"
),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=1, activation="sigmoid"),
]
Step 6: Create Model
gen_optimizer = tf.keras.optimizers.Adam(0.0001, beta_1=0.5)
disc_optimizer = tf.keras.optimizers.RMSprop(0.0005)
model = WGAN(
gen = generator,
disc = discriminator,
gen_optimizer = gen_optimizer,
disc_optimizer = disc_optimizer,
n_Z = N_Z,
gradient_penalty_weight = 10.0
)
Step 7: Train the model
# exampled data for plotting results
defplot_reconstruction(model, nex=8, zm=2):
samples = model.generate(tf.random.normal(shape=(BATCH_SIZE, N_Z)))
fig, axs = plt.subplots(ncols=nex, nrows=1, figsize=(zm * nex, zm))
for axi in range(nex):
axs[axi].matshow(
samples.numpy()[axi].squeeze(), cmap=plt.cm.Greys, vmin=0, vmax=1
)
axs[axi].axis('off')
plt.show()
losses = pd.DataFrame(columns = ['disc_loss', 'gen_loss'])n_epochs = 100
for epoch in range(n_epochs):
# train
for batch, train_x in tqdm(
zip(range(N_TRAIN_BATCHES), train_dataset), total=N_TRAIN_BATCHES
):
model.train(train_x)
# test on holdout
loss = []
for batch, test_x in tqdm(
zip(range(N_TEST_BATCHES), test_dataset), total=N_TEST_BATCHES
):
loss.append(model.compute_loss(train_x))
losses.loc[len(losses)] = np.mean(loss, axis=0)
# plot results
display.clear_output()
print(
"Epoch: {} | disc_loss: {} | gen_loss: {}".format(
epoch, losses.disc_loss.values[-1], losses.gen_loss.values[-1]
)
)
plot_reconstruction(model)
Output

plt.plot(losses.gen_loss.values)Output
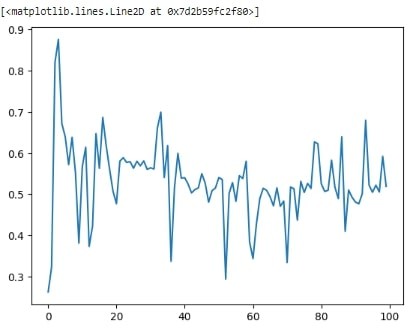
plt.plot(losses.disc_loss.values)Output
VAE-GAN
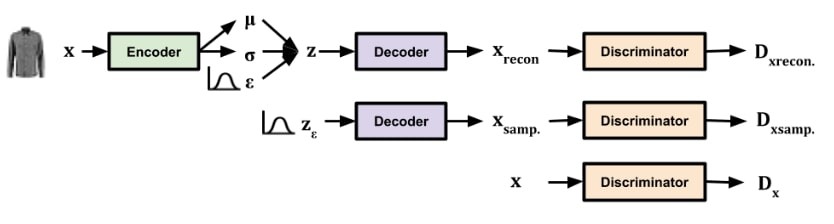
The hybrid method known as VAE-GAN enhances the realism of produced samples by combining the strengths of GANs and VAEs. It generates different data across several domains, including as text, audio, and pictures, using adversarial training and latent space modeling.
In order to outperform the pixelwise error function used in autoencoders, VAE-GAN combines the VAE and GAN to autoencode over a latent representation of data in the generator.
Step 1: Install packages if in colab
defrun_subprocess_command(cmd):
process = subprocess.Popen(cmd.split(), stdout=subprocess.PIPE)
for line in process.stdout:
print(line.decode().strip())
import sys, subprocess
IN_COLAB = "google.colab"in sys.modules
colab_requirements = [
"pip install tf-nightly-gpu-2.0-preview==2.0.0.dev20190513",
"pip install tfp-nightly==0.7.0.dev20190508",
]
if IN_COLAB:
for i in colab_requirements:
run_subprocess_command(i)
Step 2: load packages
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tqdm.autonotebook import tqdm
%matplotlib inline
from IPython import display
import pandas as pd
import tensorflow_probability as tfp
ds = tfp.distributions
Step 3: Create a fashion-MNIST dataset
TRAIN_BUF=60000
BATCH_SIZE=64
TEST_BUF=10000
DIMS = (28,28,1)
N_TRAIN_BATCHES =int(TRAIN_BUF/BATCH_SIZE)
N_TEST_BATCHES = int(TEST_BUF/BATCH_SIZE)
# load dataset
(train_images, _), (test_images, _) = tf.keras.datasets.fashion_mnist.load_data()
# split dataset
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype(
"float32"
) / 255.0
test_images = test_images.reshape(test_images.shape[0], 28, 28, 1).astype("float32") / 255.0
# batch datasets
train_dataset = (
tf.data.Dataset.from_tensor_slices(train_images)
.shuffle(TRAIN_BUF)
.batch(BATCH_SIZE)
)
test_dataset = (
tf.data.Dataset.from_tensor_slices(test_images)
.shuffle(TEST_BUF)
.batch(BATCH_SIZE)
)
Step 4: Define the network as tf.keras.model object
classVAEGAN(tf.keras.Model):"""a VAEGAN class for tensorflow
Extends:
tf.keras.Model
"""
def__init__(self, **kwargs):
super(VAEGAN, self).__init__()
self.__dict__.update(kwargs)
self.enc = tf.keras.Sequential(self.enc)
self.dec = tf.keras.Sequential(self.dec)
inputs, disc_l, outputs = self.vae_disc_function()
self.disc = tf.keras.Model(inputs=[inputs], outputs=[outputs, disc_l])
self.enc_optimizer = tf.keras.optimizers.Adam(self.lr_base_gen, beta_1=0.5)
self.dec_optimizer = tf.keras.optimizers.Adam(self.lr_base_gen, beta_1=0.5)
self.disc_optimizer = tf.keras.optimizers.Adam(self.get_lr_d, beta_1=0.5)
defencode(self, x):
mu, sigma = tf.split(self.enc(x), num_or_size_splits=2, axis=1)
return mu, sigma
defdist_encode(self, x):
mu, sigma = self.encode(x)
return ds.MultivariateNormalDiag(loc=mu, scale_diag=sigma)
defget_lr_d(self):
return self.lr_base_disc * self.D_prop
defdecode(self, z):
return self.dec(z)
defdiscriminate(self, x):
return self.disc(x)
defreconstruct(self, x):
mean, _ = self.encode(x)
return self.decode(mean)
defreparameterize(self, mean, logvar):
eps = tf.random.normal(shape=mean.shape)
return eps * tf.exp(logvar * 0.5) + mean
# @tf.function
defcompute_loss(self, x):
# pass through network
q_z = self.dist_encode(x)
z = q_z.sample()
p_z = ds.MultivariateNormalDiag(
loc=[0.0] * z.shape[-1], scale_diag=[1.0] * z.shape[-1]
)
xg = self.decode(z)
z_samp = tf.random.normal([x.shape[0], 1, 1, z.shape[-1]])
xg_samp = self.decode(z_samp)
d_xg, ld_xg = self.discriminate(xg)
d_x, ld_x = self.discriminate(x)
d_xg_samp, ld_xg_samp = self.discriminate(xg_samp)
# GAN losses
disc_real_loss = gan_loss(logits=d_x, is_real=True)
disc_fake_loss = gan_loss(logits=d_xg_samp, is_real=False)
gen_fake_loss = gan_loss(logits=d_xg_samp, is_real=True)
discrim_layer_recon_loss = (
tf.reduce_mean(tf.reduce_mean(tf.math.square(ld_x - ld_xg), axis=0))
/ self.recon_loss_div
)
self.D_prop = sigmoid(
disc_fake_loss - gen_fake_loss, shift=0.0, mult=self.sig_mult
)
kl_div = ds.kl_divergence(q_z, p_z)
latent_loss = tf.reduce_mean(tf.maximum(kl_div, 0)) / self.latent_loss_div
return (
self.D_prop,
latent_loss,
discrim_layer_recon_loss,
gen_fake_loss,
disc_fake_loss,
disc_real_loss,
)
# @tf.function
defcompute_gradients(self, x):
with tf.GradientTape() as enc_tape, tf.GradientTape() as dec_tape, tf.GradientTape() as disc_tape:
(
_,
latent_loss,
discrim_layer_recon_loss,
gen_fake_loss,
disc_fake_loss,
disc_real_loss,
) = self.compute_loss(x)
enc_loss = latent_loss + discrim_layer_recon_loss
dec_loss = gen_fake_loss + discrim_layer_recon_loss
disc_loss = disc_fake_loss + disc_real_loss
enc_gradients = enc_tape.gradient(enc_loss, self.enc.trainable_variables)
dec_gradients = dec_tape.gradient(dec_loss, self.dec.trainable_variables)
disc_gradients = disc_tape.gradient(disc_loss, self.disc.trainable_variables)
return enc_gradients, dec_gradients, disc_gradients
@tf.function
defapply_gradients(self, enc_gradients, dec_gradients, disc_gradients):
self.enc_optimizer.apply_gradients(
zip(enc_gradients, self.enc.trainable_variables)
)
self.dec_optimizer.apply_gradients(
zip(dec_gradients, self.dec.trainable_variables)
)
self.disc_optimizer.apply_gradients(
zip(disc_gradients, self.disc.trainable_variables)
)
deftrain(self, x):
enc_gradients, dec_gradients, disc_gradients = self.compute_gradients(x)
self.apply_gradients(enc_gradients, dec_gradients, disc_gradients)
defgan_loss(logits, is_real=True):
"""Computes standard gan loss between logits and labels
Arguments:
logits {[type]} -- output of discriminator
Keyword Arguments:
isreal {bool} -- whether labels should be 0 (fake) or 1 (real) (default: {True})
"""
if is_real:
labels = tf.ones_like(logits)
else:
labels = tf.zeros_like(logits)
return tf.compat.v1.losses.sigmoid_cross_entropy(
multi_class_labels=labels, logits=logits
)
defsigmoid(x, shift=0.0, mult=20):
""" squashes a value with a sigmoid
"""
return tf.constant(1.0) / (
tf.constant(1.0) + tf.exp(-tf.constant(1.0) * (x * mult))
)
Step 5: Define the network architecture
GAIA has an autoencoder as its generator, and a UNET as its descriminator.
N_Z = 128encoder = [
tf.keras.layers.InputLayer(input_shape=DIMS),
tf.keras.layers.Conv2D(
filters=32, kernel_size=3, strides=(2, 2), activation="relu"
),
tf.keras.layers.Conv2D(
filters=64, kernel_size=3, strides=(2, 2), activation="relu"
),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=N_Z*2),
]
decoder = [
tf.keras.layers.Dense(units=7 * 7 * 64, activation="relu"),
tf.keras.layers.Reshape(target_shape=(7, 7, 64)),
tf.keras.layers.Conv2DTranspose(
filters=64, kernel_size=3, strides=(2, 2), padding="SAME", activation="relu"
),
tf.keras.layers.Conv2DTranspose(
filters=32, kernel_size=3, strides=(2, 2), padding="SAME", activation="relu"
),
tf.keras.layers.Conv2DTranspose(
filters=1, kernel_size=3, strides=(1, 1), padding="SAME", activation="sigmoid"
),
]
defvaegan_discrim():
inputs = tf.keras.layers.Input(shape=(28, 28, 1))
conv1 = tf.keras.layers.Conv2D(
filters=32, kernel_size=3, strides=(2, 2), activation="relu"
)(inputs)
conv2 = tf.keras.layers.Conv2D(
filters=64, kernel_size=3, strides=(2, 2), activation="relu"
)(conv1)
flatten = tf.keras.layers.Flatten()(conv2)
lastlayer = tf.keras.layers.Dense(units=512, activation="relu")(flatten)
outputs = tf.keras.layers.Dense(units=1, activation = None)(lastlayer)
return inputs, lastlayer, outputs
Step 6: Create Model
gen_optimizer = tf.keras.optimizers.Adam(1e-3, beta_1=0.5)
disc_optimizer = tf.keras.optimizers.RMSprop(1e-3)
model = VAEGAN(
enc = encoder,
dec = decoder,
vae_disc_function = vaegan_discrim,
lr_base_gen = 1e-3, #
lr_base_disc = 1e-4, # the discriminator's job is easier than the generators so make the learning rate lower
latent_loss_div=1, # this variable will depend on your dataset - choose a number that will bring your latent loss to ~1-10
sig_mult = 10, # how binary the discriminator's learning rate is shifted (we squash it with a sigmoid)
recon_loss_div = .001, # this variable will depend on your dataset - choose a number that will bring your latent loss to ~1-10
)
Step 7: Train the model
example_data = next(iter(train_dataset))model.train(example_data)defplot_reconstruction(model, example_data, nex=8, zm=2):
example_data_reconstructed = model.reconstruct(example_data)
samples = model.decode(tf.random.normal(shape=(BATCH_SIZE, N_Z)))
fig, axs = plt.subplots(ncols=nex, nrows=3, figsize=(zm * nex, zm * 3))
for axi, (dat, lab) in enumerate(
zip(
[example_data, example_data_reconstructed, samples],
["data", "data recon", "samples"],
)
):
for ex in range(nex):
axs[axi, ex].matshow(
dat.numpy()[ex].squeeze(), cmap=plt.cm.Greys, vmin=0, vmax=1
)
axs[axi, ex].axes.get_xaxis().set_ticks([])
axs[axi, ex].axes.get_yaxis().set_ticks([])
axs[axi, 0].set_ylabel(lab)
plt.show()
defplot_losses(losses):
fig, axs =plt.subplots(ncols = 4, nrows = 1, figsize= (16,4))
axs[0].plot(losses.latent_loss.values, label = 'latent_loss')
axs[1].plot(losses.discrim_layer_recon_loss.values, label = 'discrim_layer_recon_loss')
axs[2].plot(losses.disc_real_loss.values, label = 'disc_real_loss')
axs[2].plot(losses.disc_fake_loss.values, label = 'disc_fake_loss')
axs[2].plot(losses.gen_fake_loss.values, label = 'gen_fake_loss')
axs[3].plot(losses.d_prop.values, label = 'd_prop')
for ax in axs.flatten():
ax.legend()
plt.show()
# a pandas dataframe to save the loss information to
losses = pd.DataFrame(columns=[
'd_prop',
'latent_loss',
'discrim_layer_recon_loss',
'gen_fake_loss',
'disc_fake_loss',
'disc_real_loss',
])
n_epochs = 200
for epoch in range(n_epochs):
# train
for batch, train_x in tqdm(
zip(range(N_TRAIN_BATCHES), train_dataset), total=N_TRAIN_BATCHES
):
model.train(train_x)
# test on holdout
loss = []
for batch, test_x in tqdm(
zip(range(N_TEST_BATCHES), train_dataset), total=N_TEST_BATCHES
):
loss.append(model.compute_loss(train_x))
losses.loc[len(losses)] = np.mean(loss, axis=0)
# plot results
display.clear_output()
print(
"Epoch: {}".format(epoch)
)
plot_reconstruction(model, example_data)
plot_losses(losses)
Output
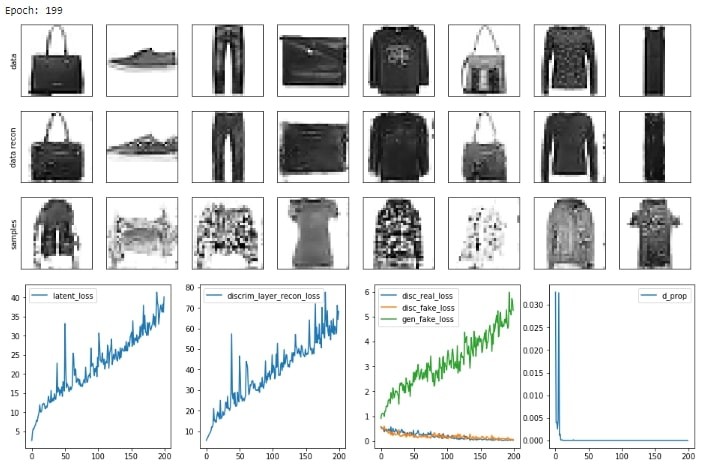
Conclusion
The Fashion-MNIST dataset has been used to test two sophisticated generative adversarial networks (GANs): Variational Autoencoder GAN (VAE-GAN) and Wasserstein GAN with Gradient Penalty (WGAN-GP). While VAE-GAN combines VAEs with GANs for improved data distribution capture, WGAN-GP uses a gradient penalty term and Wasserstein distance metric to increase training stability and convergence.