- Getting Started with Generative Artificial Intelligence
- Mastering Image Generation Techniques with Generative Models
- Generating Art with Neural Style Transfer
- Exploring Deep Dream and Neural Style Transfer
- A Guide to 3D Object Generation with Generative Models
- Text Generation with Generative Models
- Language Generation Models for Prompt Generation
- Chatbots with Generative AI Models
- Music Generation with Generative Models
- A Beginner’s Guide to Generative Design
- Video Generation with Generative Models
- Anime Generation with Generative Models
- Generative Adversarial Networks (GANs)
- Generative modeling using Variational AutoEncoders
- Reinforcement Learning for Generation
- Interactive Generative Systems
- Fashion Generation with Generative Models
- Story Generation with Generative Models
- Character Generation with Generative AI
- Generative Modeling for Simulation
- Data Augmentation Techniques with Generative Models
- Future Directions in Generative AI
Video Generation with Generative Models | Generative AI

Introduction
Generative models have revolutionized artificial intelligence, particularly in multimedia synthesis. Video generation, the creation of coherent sequences of frames, poses unique challenges requiring an understanding of temporal dynamics. In this tutorial, we explore the fusion of deep learning with video data, discussing techniques, challenges, and applications. By the end, participants will grasp both fundamentals and cutting-edge advancements in video synthesis.
Importance of Video Generation with Generative Models
Video generation with generative models holds immense importance across various domains. It enables the creation of realistic and dynamic video content, revolutionizing industries such as entertainment, healthcare, education, and security. By mastering this technology, we unlock unprecedented potential for innovation and advancement in numerous fields.
Let’s dive into these Video Generation with Generative Models
- Diffusion-based text-to-video generation model
Overview Video Generation with Diffusion-based text-to-video generation model
The diffusion model of text-to-video generation is composed of three sub-networks: the video latent space to video visual space model, the text feature extraction model, and the text feature-to-video latent space diffusion model. A total of 1.7 billion parameters make up the model. This version only allows input in English. Utilizing an iterative denoising procedure from the pure Gaussian noise video, the diffusion model generates videos using a UNet3D structure.
The Workflow
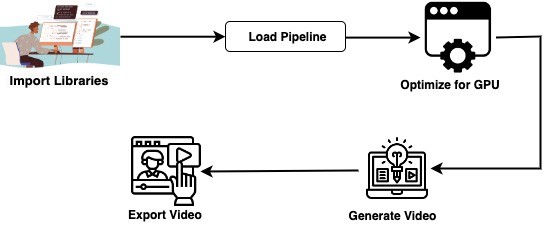
Implementation of Video Generation using Diffusion-based text-to-video generation model
Let’s go through a simple code to understand things better:
Step 1: Installing Dependencies
$ pip install diffusers transformers accelerate torch
Step 2: Import Libraries
import torch
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
from diffusers.utils import export_to_video
Step 3: Initializing Diffusion Model Pipeline
The code uses a DPMSolverMultistepScheduler for task scheduling, initializes a DiffusionPipeline for text-to-video jobs, configures it with a more efficient torch float16 data type, and maximizes speed by leveraging parallel CPU processing.
pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
Step 4: Text-to-Video Processing
The code turns the text prompt "Spiderman is surfing" into a video by processing it through a pipeline and exports the generated frames into a video file.
prompt = "Spiderman is surfing"
video_frames = pipe(prompt, num_inference_steps=25).frames
video_path = export_to_video(video_frames)
Long Video Generation
Using Torch 2.0, VAE slicing, and attentiveness may all help you optimize memory use. With less than 16GB of GPU VRAM, you should be able to create films for up to 25 seconds with this.
Step 1: Installing Dependencies
!pip install git+https://github.com/huggingface/diffusers transformers accelerate
Step 2: Import Libraries
import torch
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
from diffusers.utils import export_to_video
Step 3: Load pipeline
The code loads a pre-trained model for text-to-video conversion, optimizing it for efficiency and task scheduling.
# load pipeline
pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
Step 4: optimize for GPU memory
pipe.enable_model_cpu_offload()
pipe.enable_vae_slicing()
Step 5: Generate
The code takes the provided input and creates a 200-frame, 25-inference-step film about Spider-Man and Darth Vader surfing.
prompt = "Spiderman is surfing. Darth Vader is also surfing and following Spiderman"
video_frames = pipe(prompt, num_inference_steps=25, num_frames=200).frames
Step 6: convent to video
video_path = export_to_video(video_frames)
Conclusion
Generative models are a major advance in the way that deep learning and video data fusion are transforming multimedia synthesis. This course examines a diffusion-based text-to-video generation model with 1.7 billion parameters that can produce lengthy films even on a GPU with little RAM. The model's architecture and process are described, showcasing its applicability in a number of fields, including security, education, entertainment, and healthcare. Deep learning and video data combined will spur innovation and open up new avenues for creativity and learning.