
Meta's Llama 4 models, Llama 4 Maverick and Scout, mark a major advancement in AI technology. Released on April 5, 2025, these models use a Mixture-of-Experts (MoE) system that allows them to handle both text and images efficiently, offering outstanding performance at a low cost. Developers can easily integrate these features into their apps through APIs from different platforms, making it simple and powerful to use.
Understanding Llama 4 Maverick and Scout
Understanding the main characteristics of these models first will help one use the API. Llama 4 analyzes both text and images from the onset, which means it can perform multimodal tasks without any additional training. It has a more efficient MoE (Mixture-of-Experts) architecture because it only activates a subset of its parameters on each task.
Llama 4 Scout: Fast and Efficient
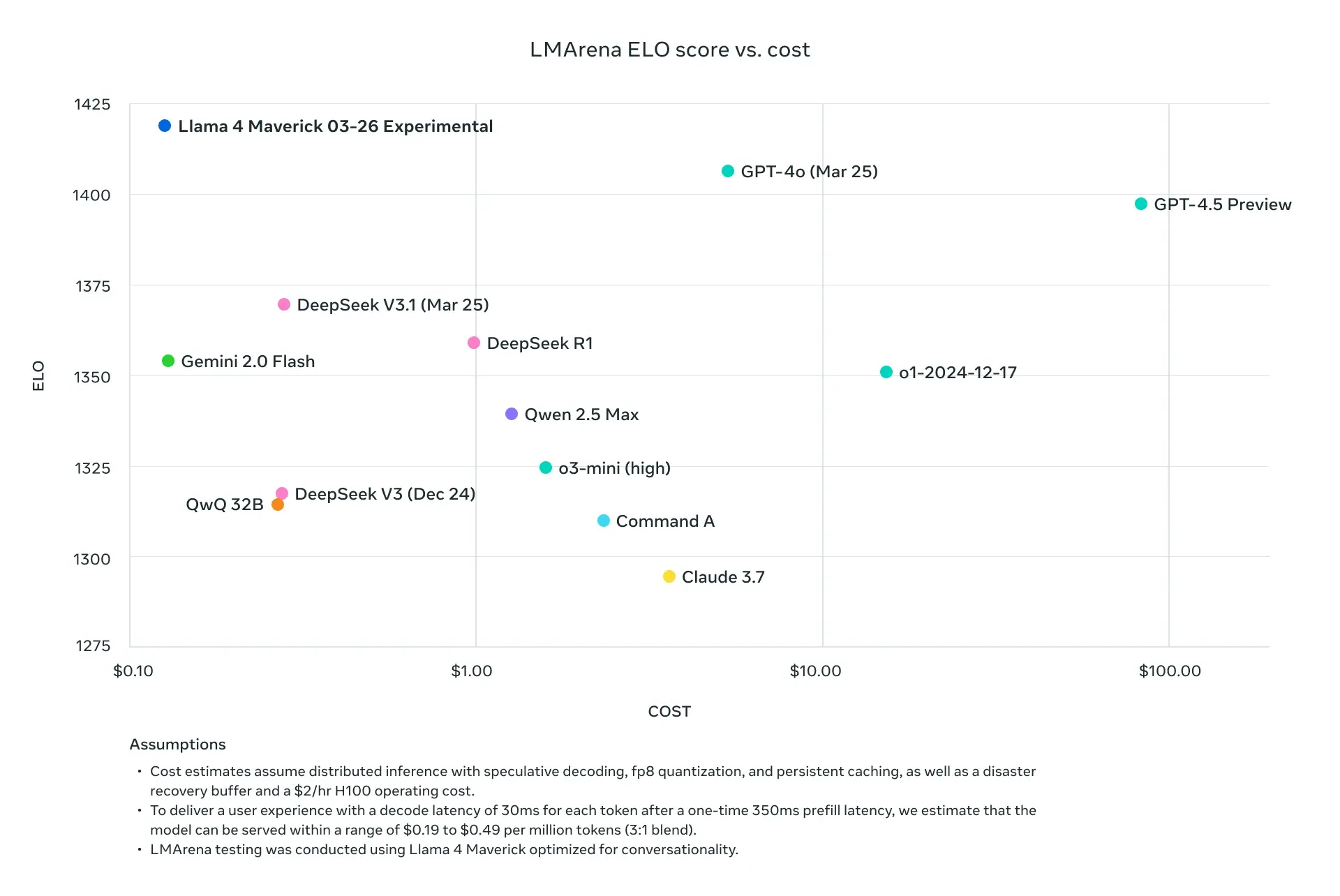
Llama 4 Scout is your go-to for quick, light tasks. It has 17 billion active parameters (109 billion total) and a huge 10 million token context window. That's perfect for big jobs like summarizing long texts or analyzing code. Running on one NVIDIA H100 GPU keeps things straightforward and inexpensive. Developers appreciate Scout for its quickness and low resource consumption.
Llama 4 Maverick: Powerful and Flexible
Llama 4 Maverick steps it up. With 17 billion active parameters (400 billion total) and a 1 million token context window, it's built for tougher tasks. It understands 12 languages-like English, Spanish, and Hindi-and excels at chat and creative writing. Need a multilingual assistant or detailed image analysis? Maverick's your pick.
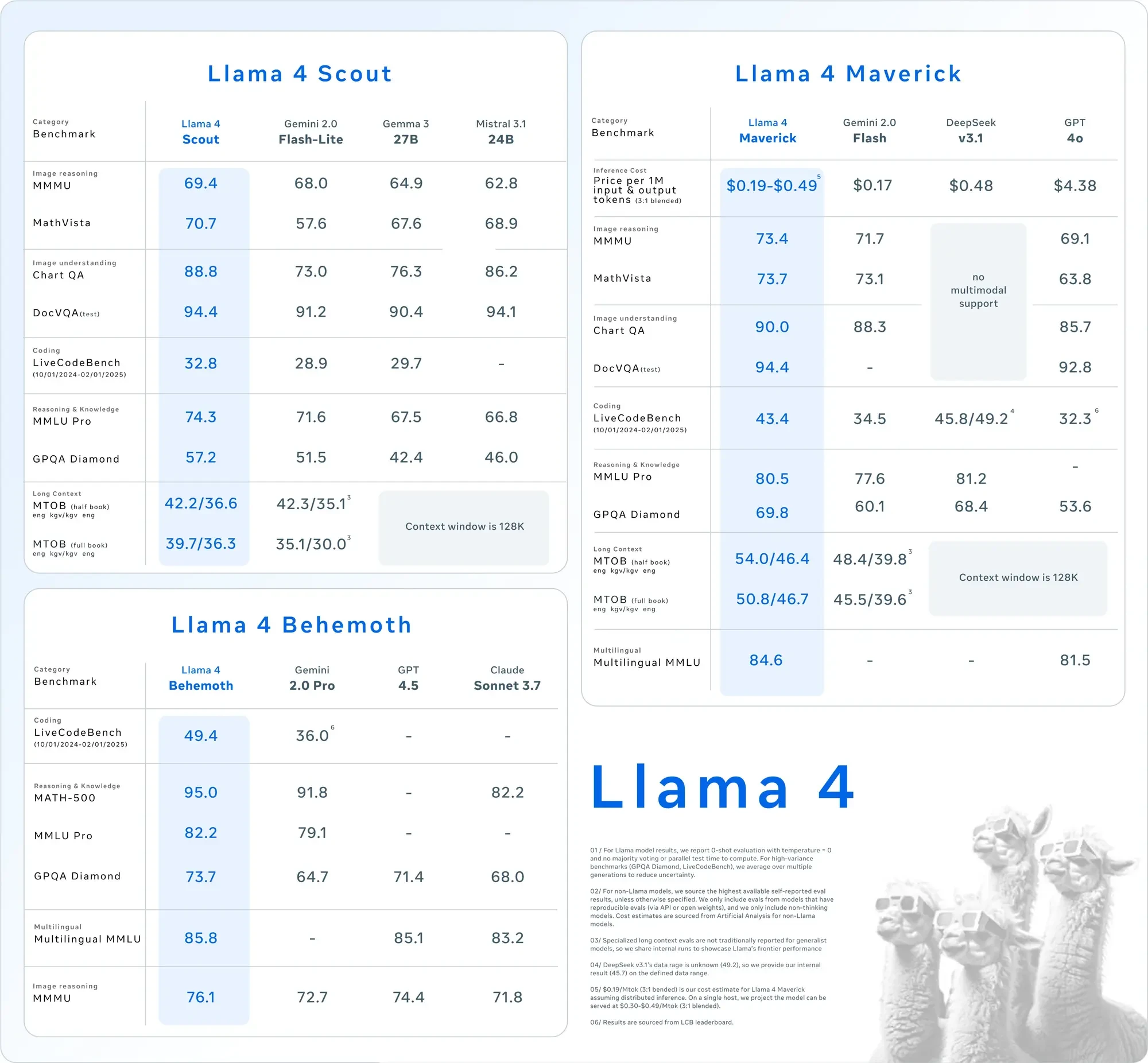
Both models are great choices for API-based projects since they outperform their predecessors, including Llama 3, and compete with industry leaders like GPT-4o.
Why Use the Llama 4 API?
Having Llama 4 embedded via API eliminates the need to host such massive models on-premises, which usually requires enormous hardware (e.g., NVIDIA H100 DGX for Maverick). Managed APIs are provided by platforms like Groq, Together AI, and OpenRouter instead.
- Scalability: Manage fluctuating demands without incurring additional infrastructure costs.
- Cost-effectiveness: Pay for each token at rates as low as $0.11/M (Groq Scout).
- Simple HTTP queries can be used to access multimodal features, making it easy to use.
Next, let's set up your environment to call these APIs.
Setting Up the Llama 4 API
Follow these instructions to configure your development environment to interface with Llama 4 Maverick and Llama 4 Scout via API:
Step 1: Choose an API Provider
There are several platforms that offer Llama 4 APIs. Some well-liked choices are listed below:
- Groq: Affordable pricing for inference (Scout: $0.11 per million inputs, Maverick: $0.50 per million inputs).
- Together AI: Provides dedicated endpoints with custom scaling options.
- OpenRouter: Offers a free tier, great for testing.
- Cloudflare Workers AI: Serverless deployment with support for Scout.
For this guide, we'll focus on Groq and Together AI because of their clear documentation, dependable performance, and ease of integration.
Step 2: Obtain API Keys
- Groq: Sign up at groq.com, go to the Developer Console, and generate your API key from there.
- Create your API key
Together AI: Go to together.ai and sign up. Once you're in, grab your API key from the dashboard.
To avoid the problem of hardcoding, store these keys safely (e.g., as environment variables).
Step 3: Install Dependencies
!pip install groq
!pip install requests
!pip install groq
!pip install requestsMaking Your First Llama 4 API Call
Now that the environment has been configured, you can make requests to the Llama 4 API. To observe it in action, let's start with a straightforward use case for text creation.
Example 1: Text Generation with Llama 4 Scout (Groq)
Here's how you can generate text using Llama 4 Scout via the Groq API.
from groq import Groq
import os
# Set your API key
os.environ["GROQ_API_KEY"] = "ADD YOUR API KEY"
client = Groq(api_key=os.environ.get("GROQ_API_KEY"))
# Your payload adapted for Groq SDK
response = client.chat.completions.create(
model="meta-llama/Llama-4-Scout-17B-16E-Instruct",
messages=[{"role": "user", "content": "Write a short poem about the moon."}],
max_tokens=100
)
print("Poem:", response.choices[0].message.content)Output:
Poem: Here is a short poem about the moon:
The moon, a glowing orb of white,
Lends magic to the dark of night.
It waxes, wanes, and shines so bright,
A constant presence, a gentle light.
Its phases mark the passage of time,
From new to full, a cycle divine.
It guides the tides and lights the way,
A beacon in the darkness, night by day.Example 2: Multimodal Input with Llama 4 Maverick (Together AI)
Maverick excels in handling multimodal tasks. Here's how you can describe an image using the API:
import requests
# Direct API key input (not recommended for public code)
API_KEY = "ADD YOUR Together AI API KEY"
URL = "https://api.together.ai/v1/chat/completions"
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://www.timelesstoys.co.za/cdn/shop/products/imagimags-108pc-magnetic-building-tiles-set-imagimags-780663.jpg?v=1626605553"} # Dog image
},
{
"type": "text",
"text": "What’s in this image?"
}
]
}],
"max_tokens": 150
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# Send the request
response = requests.post(URL, json=payload, headers=headers)
if response.status_code == 200:
print("Description:", response.json()["choices"][0]["message"]["content"])
else:
print(f"Error {response.status_code}: {response.text}")Output:
Description: The image depicts a young girl engaged in play with magnetic tiles outdoors.
**Key Elements:**
* The girl is kneeling on a blanket, wearing a gray tank top and denim shorts.
* She has curly blonde hair and is holding a tall structure made of colorful magnetic tiles.
* The structure is composed of variously colored tiles, including red, orange, yellow, green, and blue, stacked vertically to form a tower.
* The girl is adding another tile to the top of the structure.
**Background:**
* The background features trees and grass, indicating that the scene is set in a park or backyard.
* The presence of sunlight suggests a daytime setting.
**Overall Impression:**
* The image conveys a sense of creativity and joy,Optimizing API Requests for Performance
To improve efficiency in your Llama 4 API calls, consider these strategies:
- Adjust Context Length
- Scout: Use its 10M token window for handling long documents. To be on the safe side, you could increase max_model_len to handle longer inputs if the system is capable.
- Maverick: For chat applications, limit to 1M tokens to balance speed and quality.
- Fine-Tune Parameters
- Temperature: Set a lower value (e.g., 0.5) for more factual responses and a higher value (e.g., 1.0) for more creative outputs.
- Max Tokens: Reduce the length of the output to prevent calculations that are not essential.
- Batch Processing
- Send multiple prompts in a single request (if supported by the API) to reduce latency. Check your provider's documentation for batch processing endpoints.
Advanced Use Cases
Llama 4 really comes into its own for practical undertakings like this.
Case 1: Multilingual Chatbot (Maverick)
import requests
API_KEY = "ADD YOUR API KEY"
URL = "https://api.together.ai/v1/chat/completions"
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [
{"role": "user", "content": "Hola, ¿cómo puedo resetear mi contraseña?"}
],
"max_tokens": 100
}
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])Output:
**Restablecer Contraseña: Un Paso a Paso**
¡Hola! Entiendo que necesitas ayuda para resetear tu contraseña. A continuación, te proporcionaré un paso a paso detallado para que puedas hacerlo de manera segura y efectiva.
**Paso 1: Identifica la Plataforma o Servicio**
* ¿Qué plataforma o servicio estás intentando resetear la contraseña? (por ejemplo, correo electrónico, red social, cuenta bancaria, etc.)Case 2: Summarize Long Text (Scout)
from groq import Groq
import os
# Set your API key
os.environ["GROQ_API_KEY"] = "ADD YOUR GROQ API KEY"
client = Groq(api_key=os.environ.get("GROQ_API_KEY"))
# Multiline long_text for readability
long_text = "GenAI, short for Generative Artificial Intelligence, refers to AI systems capable of generating new content, ideas, or data that mimic human-like creativity. This technology leverages deep learning algorithms to produce outputs ranging from text and images to music and code, based on patterns it learns from vast datasets. GenAI uses large language models like the Generative Pre-trained Transformer (GPT) and Variational Autoencoders (VAEs) to analyze and understand the structure of the data it’s trained on, enabling the generation of novel content."
prompt = f"Summarize this: {long_text}"
response = client.chat.completions.create(
model="meta-llama/llama-4-scout-17b-16e-instruct",
messages=[{"role": "user", "content": prompt}],
max_tokens=50
)
print("Summary:", response.choices[0].message.content)Output:
Summary: Here's a summary:
**GenAI (Generative Artificial Intelligence)** is a type of AI that can generate new content, ideas, or data that mimics human creativity. It uses:
* Deep learning algorithms
* Large language models like GPT and VAComparing API Providers for Llama 4
The speed of your app as well as your budget will be influenced by selecting the appropriate supplier. This is a fast comparison:
| Provider | Model Support | Pricing (Input/Output per M) | Context Limit | Notes |
| Groq | Scout, Maverick | $0.11/$0.34 (Scout), $0.50/$0.77 (Maverick) | 128K (extensible) | Lowest cost, very high speed |
| Together AI | Scout, Maverick | Custom pricing (dedicated endpoints) | 1M (Maverick) | Scalable, enterprise-friendly |
| OpenRouter | Both | Free tier available | 128K | Ideal for testing and experimentation |
| Cloudflare | Scout | Usage-based | 131K | Easy serverless deployment |
Choose a provider based on your project's size and budget. Prototype using OpenRouter's free tier. Consider expanding with Groq for cost efficiency or Together AI for more sophisticated features as your demands increase.
Best Practices for Llama 4 API Integration
For a smooth and secure integration, keep these tips in mind:
- Rate Limiting: Follow your provider's limits (e.g., Groq allows 100 requests per minute). Use exponential backoff for retrying failed requests.
- Error Handling: Catch and record HTTP errors like 429 Too many requests to deal with issues smoothly.
- Security: Save API keys securely encrypted and always use HTTPS for API requests.
- Monitoring: Keep an eye on token usage from time to time to control costs, especially when using Maverick, which incurs more cost.
Troubleshooting Common API Issues
If you have problems, here's how to fix them:
- 401 Not Authorized: Make sure your API key is right.
- 429 Rate Limit Exceeded: Either make fewer requests or pay more for a better plan.
- Payload Errors: Make sure your request follows the correct JSON format-especially for structured fields like the messages array.
Conclusion
API integration of Llama 4 Maverick and Scout lets developers easily create sophisticated apps. Both models provide outstanding performance via simple endpoints, whether you are using Scout for its long-context efficiency or Maverick for its strong multilingual capabilities. Following this advice will help you to confidently configure, optimize, and diagnose your API requests.






